 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte Carlo Tree Search with Sampled Information Relaxation Dual Bounds
Paper and Code
Apr 20, 2017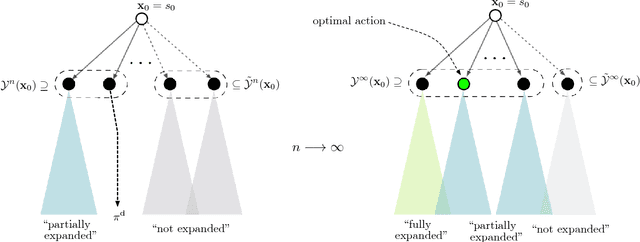
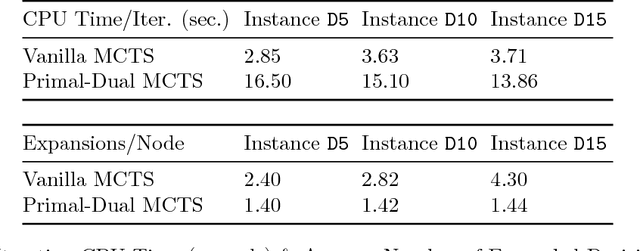
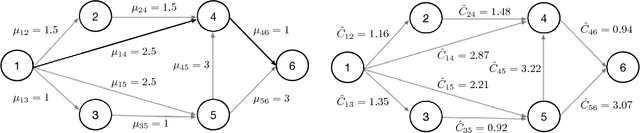
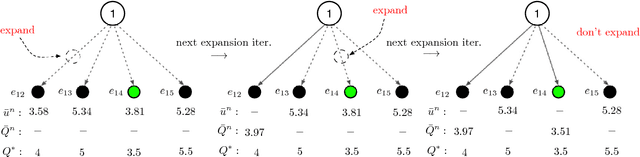
Monte Carlo Tree Search (MCTS), most famously used in game-play artificial intelligence (e.g., the game of Go), is a well-known strategy for constructing approximate solutions to sequential decision problems. Its primary innovation is the use of a heuristic, known as a default policy, to obtain Monte Carlo estimates of downstream values for states in a decision tree. This information is used to iteratively expand the tree towards regions of states and actions that an optimal policy might visit. However, to guarantee convergence to the optimal action, MCTS requires the entire tree to be expanded asymptotically. In this paper, we propose a new technique called Primal-Dual MCTS that utilizes sampled information relaxation upper bounds on potential actions, creating the possibility of "ignoring" parts of the tree that stem from highly suboptimal choices. This allows us to prove that despite converging to a partial decision tree in the limit, the recommended action from Primal-Dual MCTS is optimal. The new approach shows significant promise when used to optimize the behavior of a single driver navigating a graph while operating on a ride-sharing platform. Numerical experiments on a real dataset of 7,000 trips in New Jersey suggest that Primal-Dual MCTS improves upon standard MCTS by producing deeper decision trees and exhibits a reduced sensitivity to the size of the action space.