 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonotone Learning with Rectified Wire Networks
Paper and Code
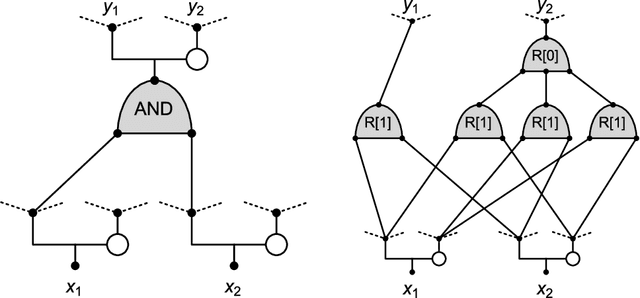

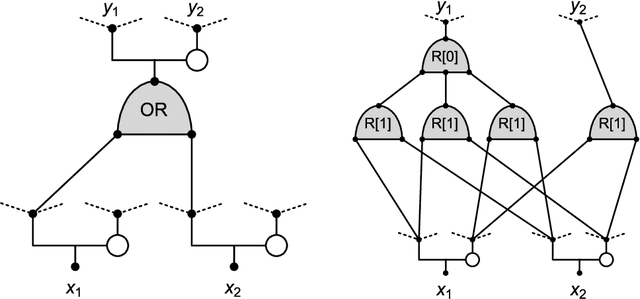

We introduce a new neural network model, together with a tractable and monotone online learning algorithm. Our model describes feed-forward networks for classification, with one output node for each class. The only nonlinear operation is rectification using a ReLU function with a bias. However, there is a rectifier on every edge rather than at the nodes of the network. There are also weights, but these are positive, static, and associated with the nodes. Our "rectified wire" networks are able to represent arbitrary Boolean functions. Only the bias parameters, on the edges of the network, are learned. Another departure in our approach, from standard neural networks, is that the loss function is replaced by a constraint. This constraint is simply that the value of the output node associated with the correct class should be zero. Our model has the property that the exact norm-minimizing parameter update, required to correctly classify a training item, is the solution to a quadratic program that can be computed with a few passes through the network. We demonstrate a training algorithm using this update, called sequential deactivation (SDA), on MNIST and some synthetic datasets. Upon adopting a natural choice for the nodal weights, SDA has no hyperparameters other than those describing the network structure. Our experiments explore behavior with respect to network size and depth in a family of sparse expander networks.