 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling Lips-State Detection Using CNN for Non-Verbal Communications
Paper and Code
Dec 11, 2021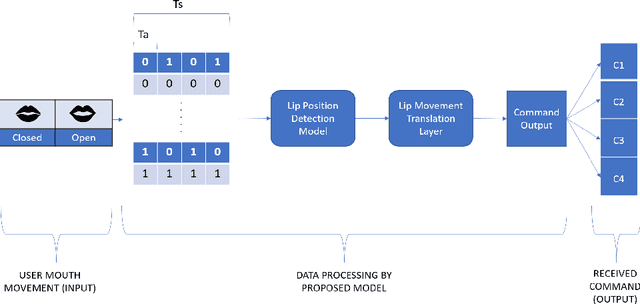
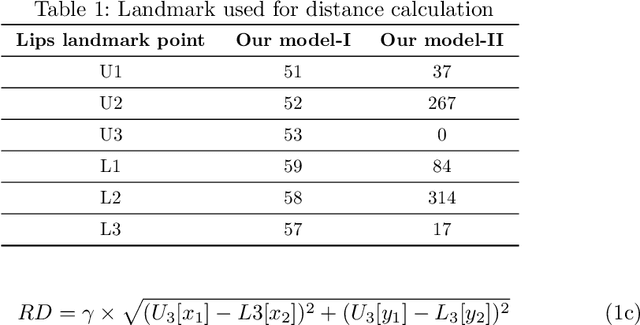
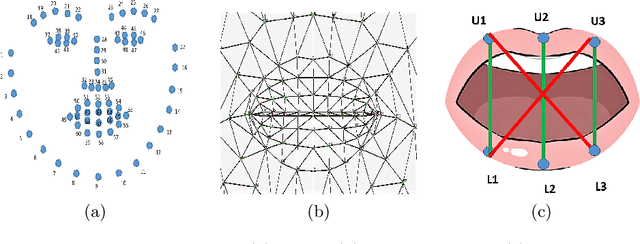
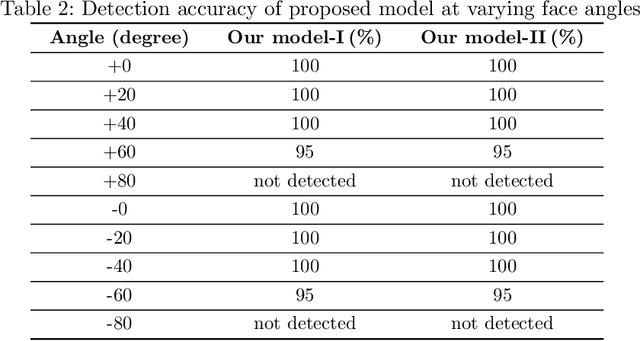
Vision-based deep learning models can be promising for speech-and-hearing-impaired and secret communications. While such non-verbal communications are primarily investigated with hand-gestures and facial expressions, no research endeavour is tracked so far for the lips state (i.e., open/close)-based interpretation/translation system. In support of this development, this paper reports two new Convolutional Neural Network (CNN) models for lips state detection. Building upon two prominent lips landmark detectors, DLIB and MediaPipe, we simplify lips-state model with a set of six key landmarks, and use their distances for the lips state classification. Thereby, both the models are developed to count the opening and closing of lips and thus, they can classify a symbol with the total count. Varying frame-rates, lips-movements and face-angles are investigated to determine the effectiveness of the models. Our early experimental results demonstrate that the model with DLIB is relatively slower in terms of an average of 6 frames per second (FPS) and higher average detection accuracy of 95.25%. In contrast, the model with MediaPipe offers faster landmark detection capability with an average FPS of 20 and detection accuracy of 94.4%. Both models thus could effectively interpret the lips state for non-verbal semantics into a natural language.