 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Online Behavior in Recommender Systems: The Importance of Temporal Context
Paper and Code
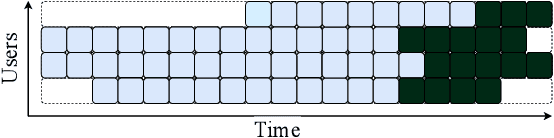
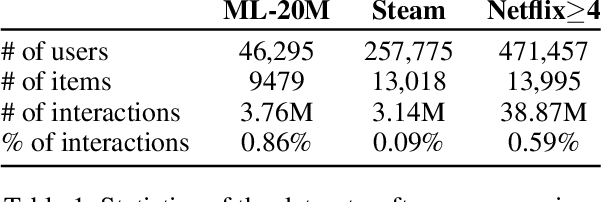
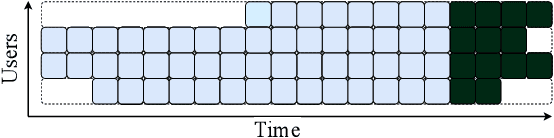
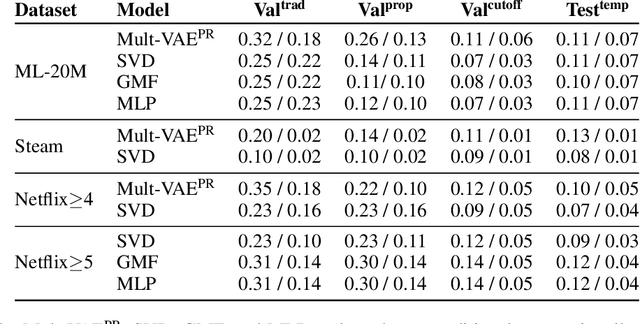
Simulating online recommender system performance is notoriously difficult and the discrepancy between the online and offline behaviors is typically not accounted for in offline evaluations. Recommender systems research tends to evaluate model performance on randomly sampled targets, yet the same systems are later used to predict user behavior sequentially from a fixed point in time. This disparity permits weaknesses to go unnoticed until the model is deployed in a production setting. We first demonstrate how omitting temporal context when evaluating recommender system performance leads to false confidence. To overcome this, we propose an offline evaluation protocol modeling the real-life use-case that simultaneously accounts for temporal context. Next, we propose a training procedure to further embed the temporal context in existing models: we introduce it in a multi-objective approach to traditionally time-unaware recommender systems. We confirm the advantage of adding a temporal objective via the proposed evaluation protocol. Finally, we validate that the Pareto Fronts obtained with the added objective dominate those produced by state-of-the-art models that are only optimized for accuracy on three real-world publicly available datasets. The results show that including our temporal objective can improve recall@20 by up to 20%.