Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Grasp Motor Imagery through Deep Conditional Generative Models
Paper and Code
Jan 11, 2017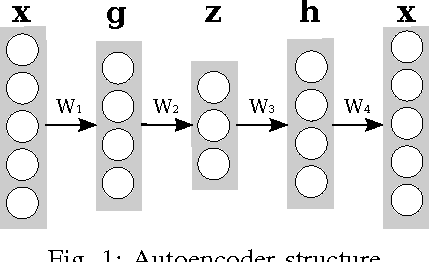
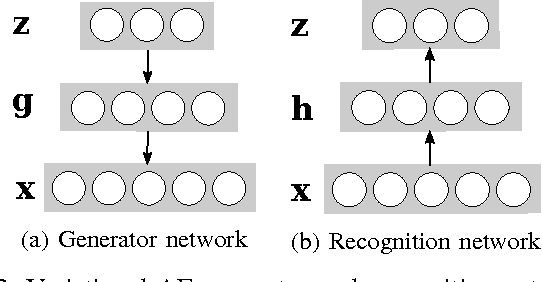
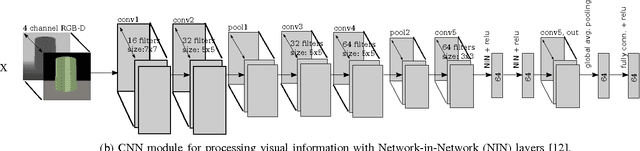
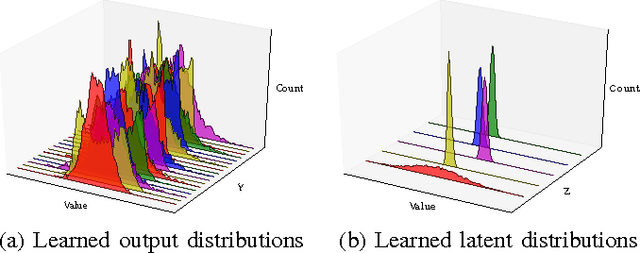
Grasping is a complex process involving knowledge of the object, the surroundings, and of oneself. While humans are able to integrate and process all of the sensory information required for performing this task, equipping machines with this capability is an extremely challenging endeavor. In this paper, we investigate how deep learning techniques can allow us to translate high-level concepts such as motor imagery to the problem of robotic grasp synthesis. We explore a paradigm based on generative models for learning integrated object-action representations, and demonstrate its capacity for capturing and generating multimodal, multi-finger grasp configurations on a simulated grasping dataset.
* Accepted for publication in Robotics and Automation Letters (RA-L)
View paper on