 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Predictive Actor-Critic: Accelerating Robot Skill Acquisition with Deep Reinforcement Learning
Paper and Code
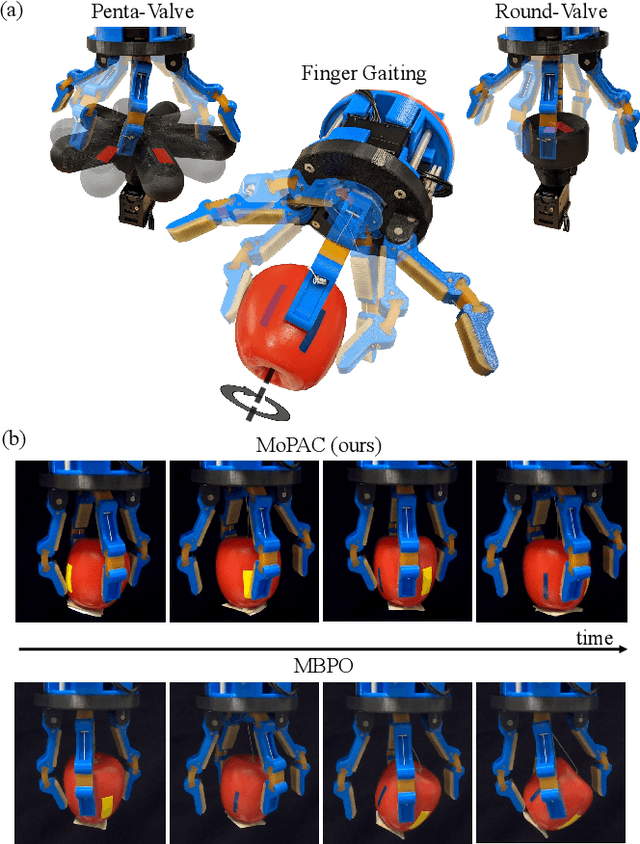
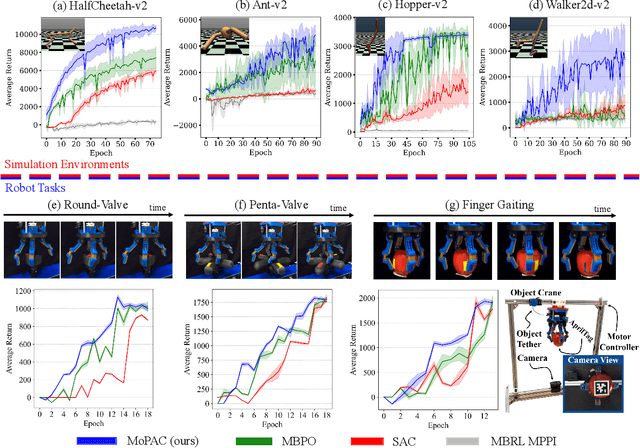
Substantial advancements to model-based reinforcement learning algorithms have been impeded by the model-bias induced by the collected data, which generally hurts performance. Meanwhile, their inherent sample efficiency warrants utility for most robot applications, limiting potential damage to the robot and its environment during training. Inspired by information theoretic model predictive control and advances in deep reinforcement learning, we introduce Model Predictive Actor-Critic (MoPAC), a hybrid model-based/model-free method that combines model predictive rollouts with policy optimization as to mitigate model bias. MoPAC leverages optimal trajectories to guide policy learning, but explores via its model-free method, allowing the algorithm to learn more expressive dynamics models. This combination guarantees optimal skill learning up to an approximation error and reduces necessary physical interaction with the environment, making it suitable for real-robot training. We provide extensive results showcasing how our proposed method generally outperforms current state-of-the-art and conclude by evaluating MoPAC for learning on a physical robotic hand performing valve rotation and finger gaiting--a task that requires grasping, manipulation, and then regrasping of an object.