 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-order selection in statistical shape models
Paper and Code
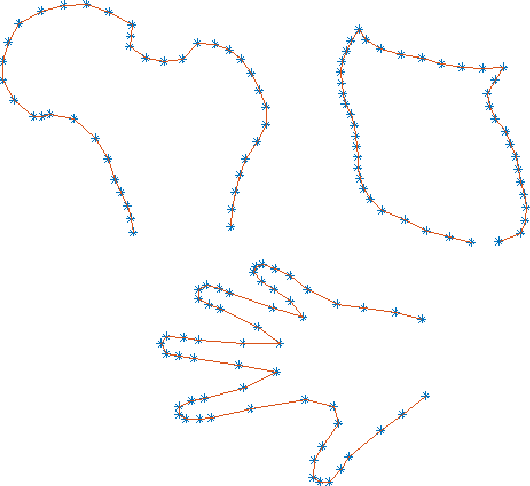
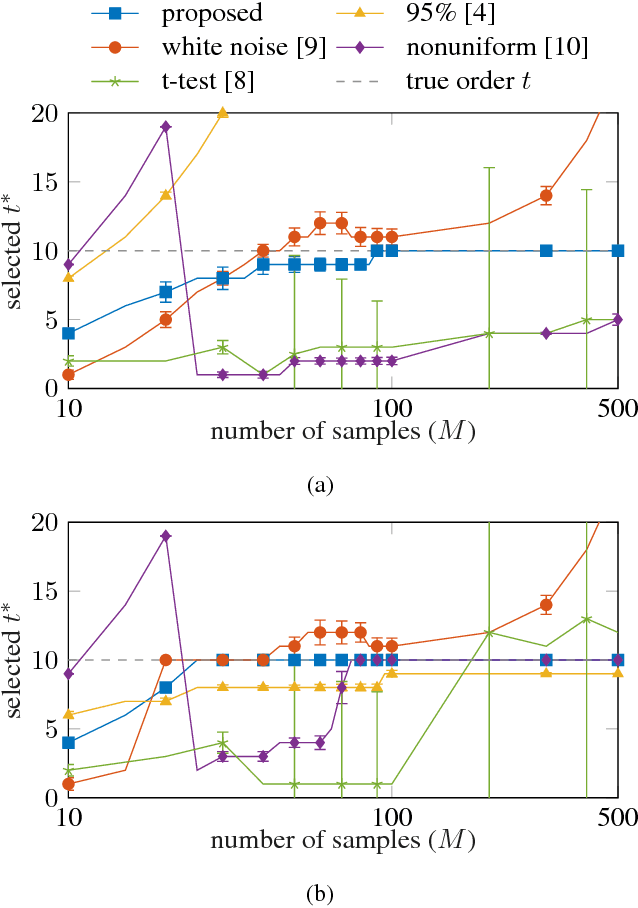
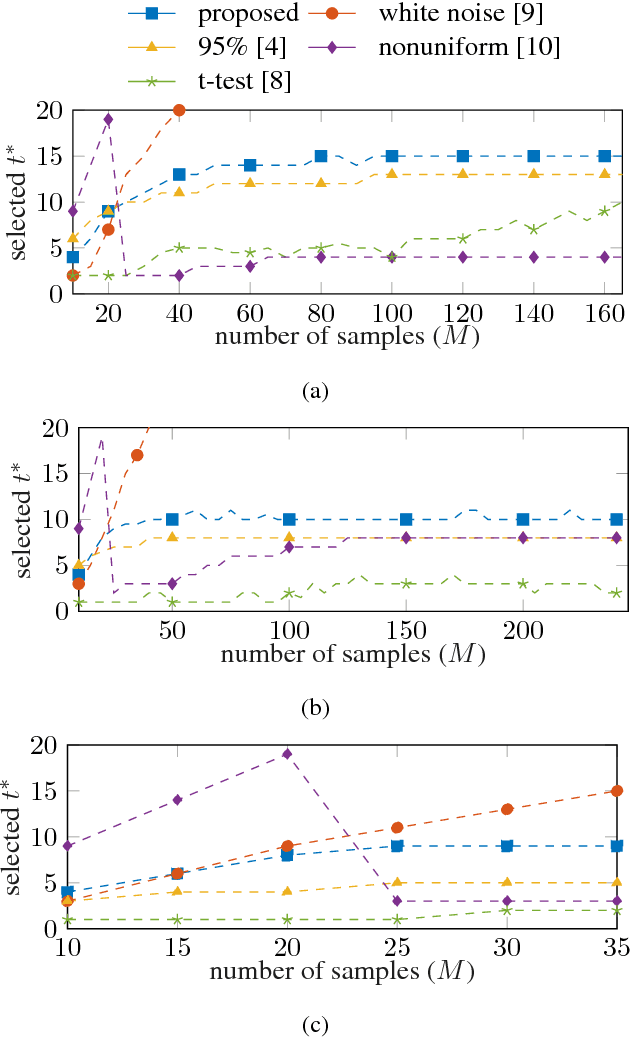
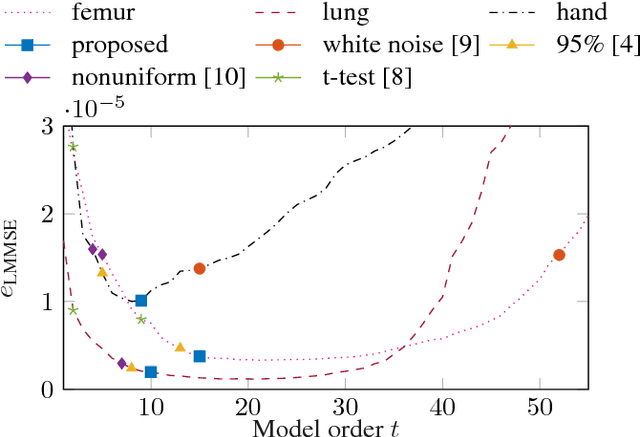
Statistical shape models enhance machine learning algorithms providing prior information about deformation. A Point Distribution Model (PDM) is a popular landmark-based statistical shape model for segmentation. It requires choosing a model order, which determines how much of the variation seen in the training data is accounted for by the PDM. A good choice of the model order depends on the number of training samples and the noise level in the training data set. Yet the most common approach for choosing the model order simply keeps a predetermined percentage of the total shape variation. In this paper, we present a technique for choosing the model order based on information-theoretic criteria, and we show empirical evidence that the model order chosen by this technique provides a good trade-off between over- and underfitting.