 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free Learning for Two-Player Zero-Sum Partially Observable Markov Games with Perfect Recall
Paper and Code
Jun 11, 2021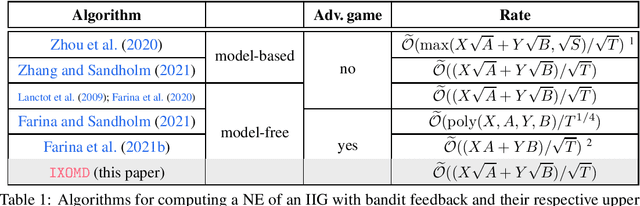
We study the problem of learning a Nash equilibrium (NE) in an imperfect information game (IIG) through self-play. Precisely, we focus on two-player, zero-sum, episodic, tabular IIG under the perfect-recall assumption where the only feedback is realizations of the game (bandit feedback). In particular, the dynamic of the IIG is not known -- we can only access it by sampling or interacting with a game simulator. For this learning setting, we provide the Implicit Exploration Online Mirror Descent (IXOMD) algorithm. It is a model-free algorithm with a high-probability bound on the convergence rate to the NE of order $1/\sqrt{T}$ where $T$ is the number of played games. Moreover, IXOMD is computationally efficient as it needs to perform the updates only along the sampled trajectory.