 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Compression by Entropy Penalized Reparameterization
Paper and Code

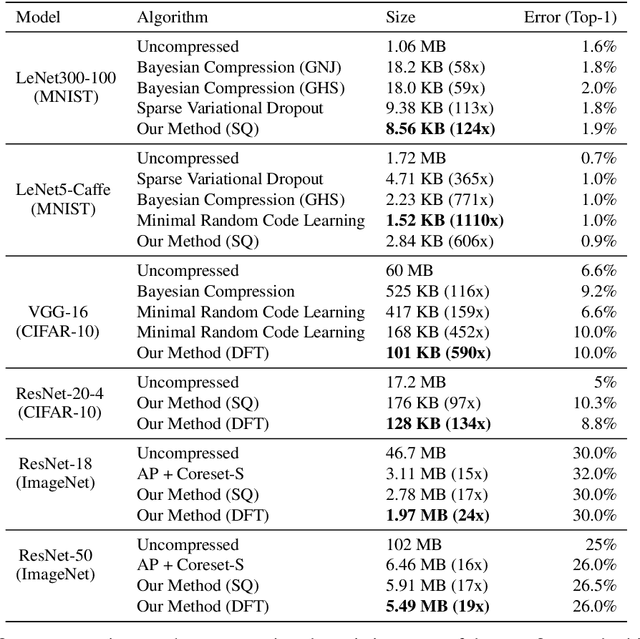

We describe an end-to-end neural network weight compression approach that draws inspiration from recent latent-variable data compression methods. The network parameters (weights and biases) are represented in a "latent" space, amounting to a reparameterization. This space is equipped with a learned probability model, which is used to impose an entropy penalty on the parameter representation during training, and to compress the representation using arithmetic coding after training. We are thus maximizing accuracy and model compressibility jointly, in an end-to-end fashion, with the rate--error trade-off specified by a hyperparameter. We evaluate our method by compressing six distinct model architectures on the MNIST, CIFAR-10 and ImageNet classification benchmarks. Our method achieves state-of-the-art compression on VGG-16, LeNet300-100 and several ResNet architectures, and is competitive on LeNet-5.