 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Uncertainty in Value Functions
Paper and Code

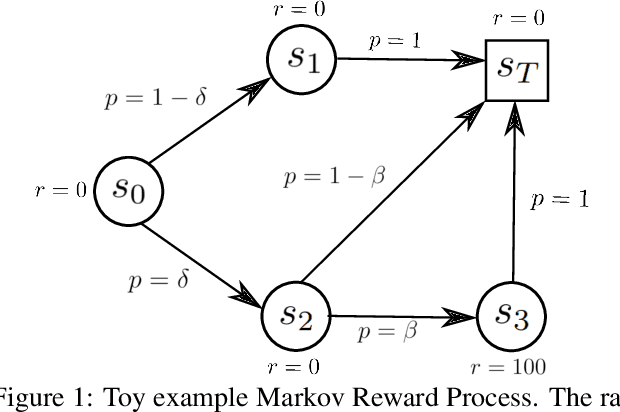
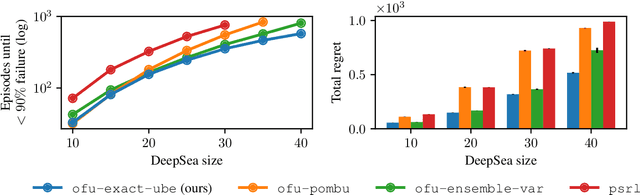
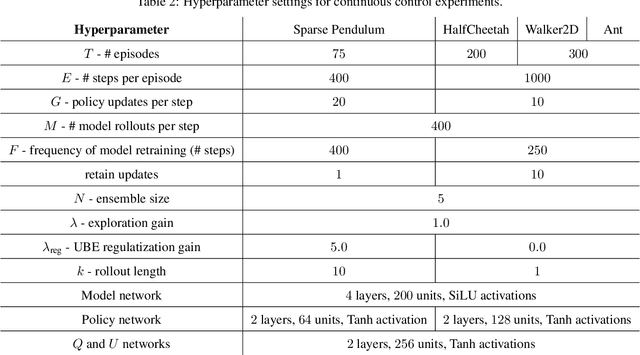
We consider the problem of quantifying uncertainty over expected cumulative rewards in model-based reinforcement learning. In particular, we focus on characterizing the variance over values induced by a distribution over MDPs. Previous work upper bounds the posterior variance over values by solving a so-called uncertainty Bellman equation, but the over-approximation may result in inefficient exploration. We propose a new uncertainty Bellman equation whose solution converges to the true posterior variance over values and explicitly characterizes the gap in previous work. Moreover, our uncertainty quantification technique is easily integrated into common exploration strategies and scales naturally beyond the tabular setting by using standard deep reinforcement learning architectures. Experiments in difficult exploration tasks, both in tabular and continuous control settings, show that our sharper uncertainty estimates improve sample-efficiency.