 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Epistemic Variance of Values for Risk-Aware Policy Optimization
Paper and Code
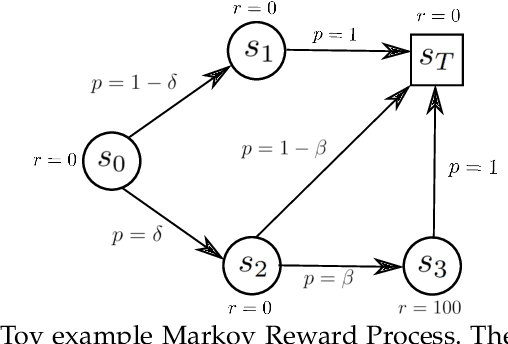



We consider the problem of quantifying uncertainty over expected cumulative rewards in model-based reinforcement learning. In particular, we focus on characterizing the variance over values induced by a distribution over MDPs. Previous work upper bounds the posterior variance over values by solving a so-called uncertainty Bellman equation (UBE), but the over-approximation may result in inefficient exploration. We propose a new UBE whose solution converges to the true posterior variance over values and leads to lower regret in tabular exploration problems. We identify challenges to apply the UBE theory beyond tabular problems and propose a suitable approximation. Based on this approximation, we introduce a general-purpose policy optimization algorithm, Q-Uncertainty Soft Actor-Critic (QU-SAC), that can be applied for either risk-seeking or risk-averse policy optimization with minimal changes. Experiments in both online and offline RL demonstrate improved performance compared to other uncertainty estimation methods.