 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMIL: A novel algorithm for disease associated cell type discovery
Paper and Code
Jun 12, 2024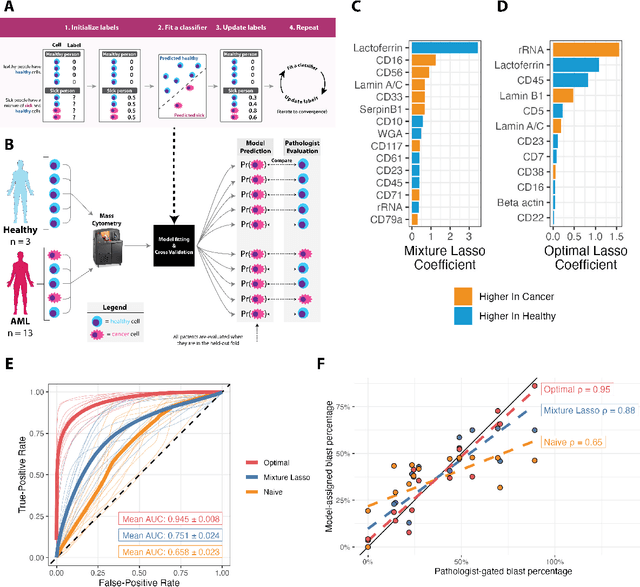

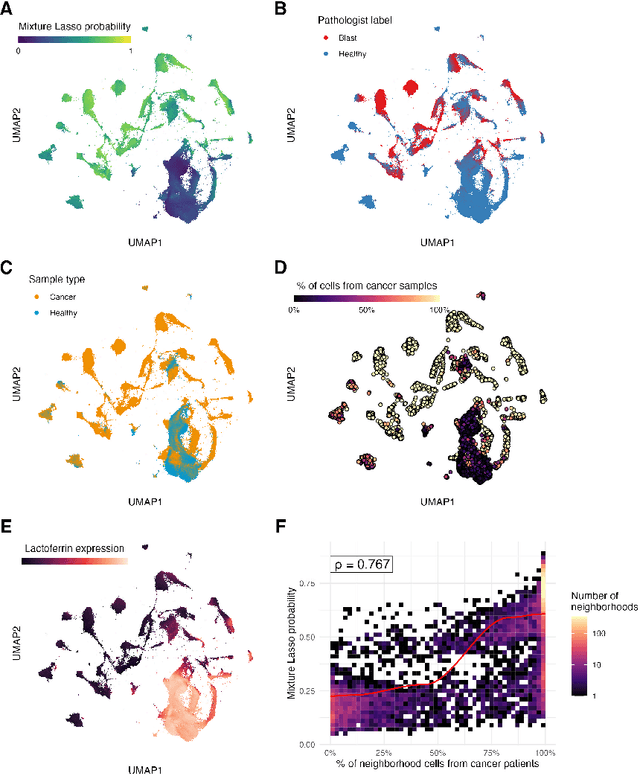
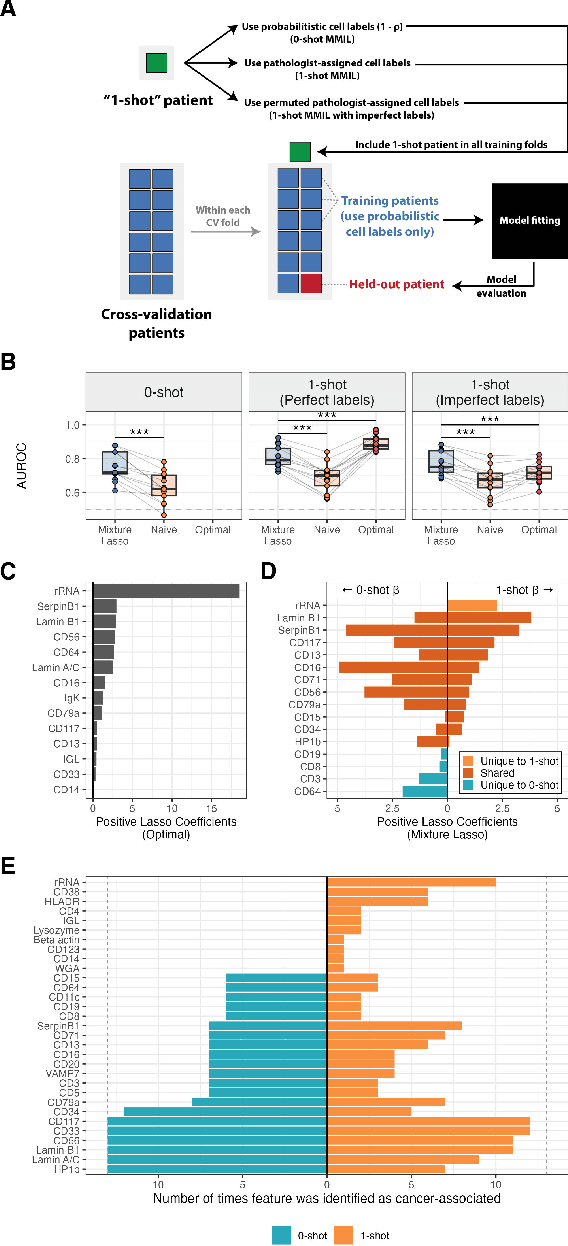
Single-cell datasets often lack individual cell labels, making it challenging to identify cells associated with disease. To address this, we introduce Mixture Modeling for Multiple Instance Learning (MMIL), an expectation maximization method that enables the training and calibration of cell-level classifiers using patient-level labels. Our approach can be used to train e.g. lasso logistic regression models, gradient boosted trees, and neural networks. When applied to clinically-annotated, primary patient samples in Acute Myeloid Leukemia (AML) and Acute Lymphoblastic Leukemia (ALL), our method accurately identifies cancer cells, generalizes across tissues and treatment timepoints, and selects biologically relevant features. In addition, MMIL is capable of incorporating cell labels into model training when they are known, providing a powerful framework for leveraging both labeled and unlabeled data simultaneously. Mixture Modeling for MIL offers a novel approach for cell classification, with significant potential to advance disease understanding and management, especially in scenarios with unknown gold-standard labels and high dimensionality.