 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing Implicit and Explicit Deep Learning with Skip DEQs and Infinite Time Neural ODEs (Continuous DEQs)
Paper and Code
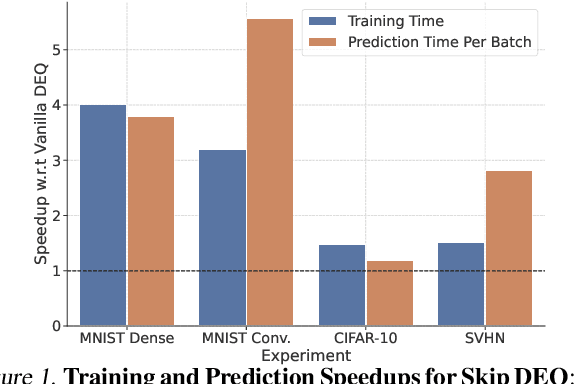
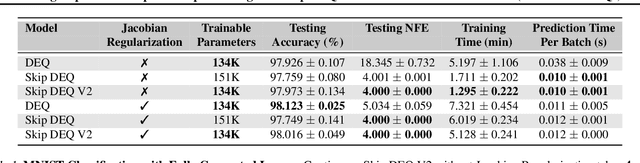
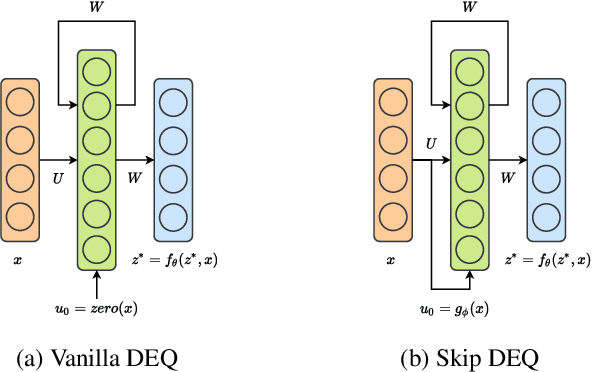
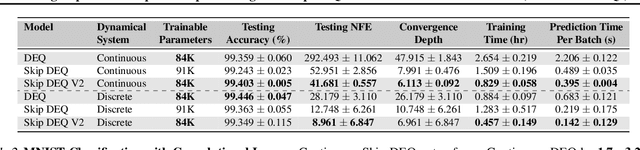
Implicit deep learning architectures, like Neural ODEs and Deep Equilibrium Models (DEQs), separate the definition of a layer from the description of its solution process. While implicit layers allow features such as depth to adapt to new scenarios and inputs automatically, this adaptivity makes its computational expense challenging to predict. Numerous authors have noted that implicit layer techniques can be more computationally intensive than explicit layer methods. In this manuscript, we address the question: is there a way to simultaneously achieve the robustness of implicit layers while allowing the reduced computational expense of an explicit layer? To solve this we develop Skip DEQ, an implicit-explicit (IMEX) layer that simultaneously trains an explicit prediction followed by an implicit correction. We show that training this explicit layer is free and even decreases the training time by 2.5x and prediction time by 3.4x. We then further increase the "implicitness" of the DEQ by redefining the method in terms of an infinite time neural ODE which paradoxically decreases the training cost over a standard neural ODE by not requiring backpropagation through time. We demonstrate how the resulting Continuous Skip DEQ architecture trains more robustly than the original DEQ while achieving faster training and prediction times. Together, this manuscript shows how bridging the dichotomy of implicit and explicit deep learning can combine the advantages of both techniques.