 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixCon3D: Synergizing Multi-View and Cross-Modal Contrastive Learning for Enhancing 3D Representation
Paper and Code

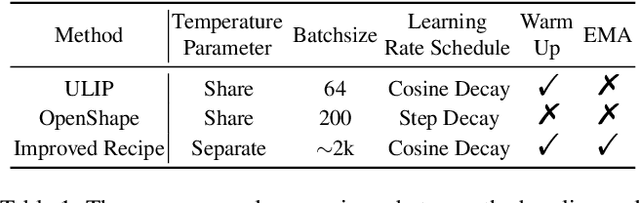


Contrastive learning has emerged as a promising paradigm for 3D open-world understanding, jointly with text, image, and point cloud. In this paper, we introduce MixCon3D, which combines the complementary information between 2D images and 3D point clouds to enhance contrastive learning. With the further integration of multi-view 2D images, MixCon3D enhances the traditional tri-modal representation by offering a more accurate and comprehensive depiction of real-world 3D objects and bolstering text alignment. Additionally, we pioneer the first thorough investigation of various training recipes for the 3D contrastive learning paradigm, building a solid baseline with improved performance. Extensive experiments conducted on three representative benchmarks reveal that our method renders significant improvement over the baseline, surpassing the previous state-of-the-art performance on the challenging 1,156-category Objaverse-LVIS dataset by 5.7%. We further showcase the effectiveness of our approach in more applications, including text-to-3D retrieval and point cloud captioning. The code is available at https://github.com/UCSC-VLAA/MixCon3D.