 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Regret for Cascading Bandits
Paper and Code
Mar 23, 2022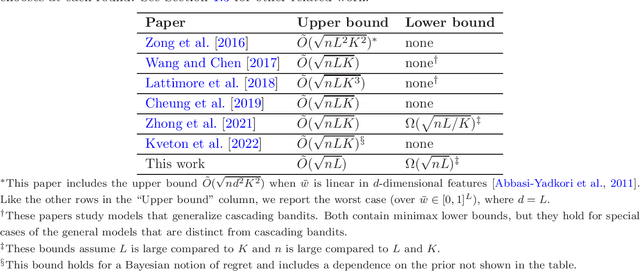
Cascading bandits model the task of learning to rank $K$ out of $L$ items over $n$ rounds of partial feedback. For this model, the minimax (i.e., gap-free) regret is poorly understood; in particular, the best known lower and upper bounds are $\Omega(\sqrt{nL/K})$ and $\tilde{O}(\sqrt{nLK})$, respectively. We improve the lower bound to $\Omega(\sqrt{nL})$ and show CascadeKL-UCB (which ranks items by their KL-UCB indices) attains it up to log terms. Surprisingly, we also show CascadeUCB1 (which ranks via UCB1) can suffer suboptimal $\Omega(\sqrt{nLK})$ regret. This sharply contrasts with standard $L$-armed bandits, where the corresponding algorithms both achieve the minimax regret $\sqrt{nL}$ (up to log terms), and the main advantage of KL-UCB is only to improve constants in the gap-dependent bounds. In essence, this contrast occurs because Pinsker's inequality is tight for hard problems in the $L$-armed case but loose (by a factor of $K$) in the cascading case.