Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Rates and Efficient Algorithms for Noisy Sorting
Paper and Code
Oct 28, 2017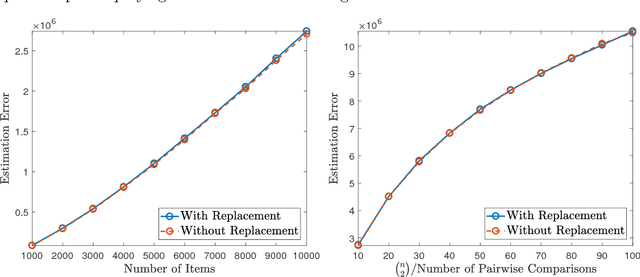
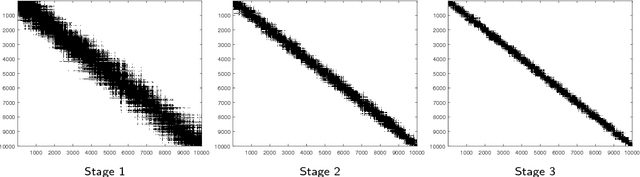
There has been a recent surge of interest in studying permutation-based models for ranking from pairwise comparison data. Despite being structurally richer and more robust than parametric ranking models, permutation-based models are less well understood statistically and generally lack efficient learning algorithms. In this work, we study a prototype of permutation-based ranking models, namely, the noisy sorting model. We establish the optimal rates of learning the model under two sampling procedures. Furthermore, we provide a fast algorithm to achieve near-optimal rates if the observations are sampled independently. Along the way, we discover properties of the symmetric group which are of theoretical interest.
* 27 pages, 2 figures
View paper on