 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimal cost feature selection of data with normal distribution measurement errors
Paper and Code
Jun 03, 2013
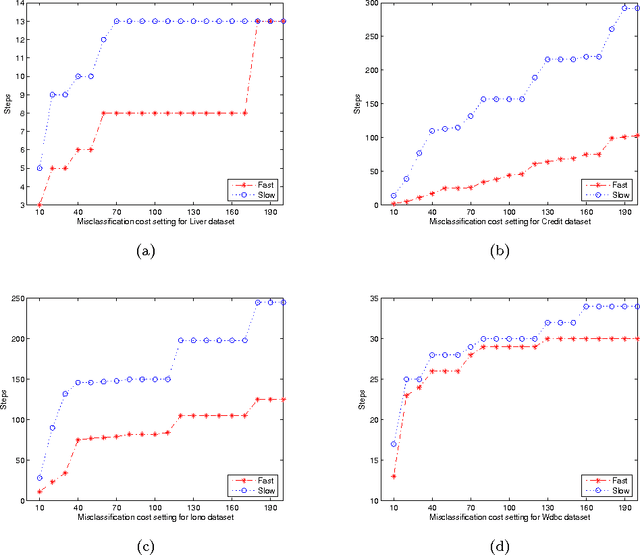

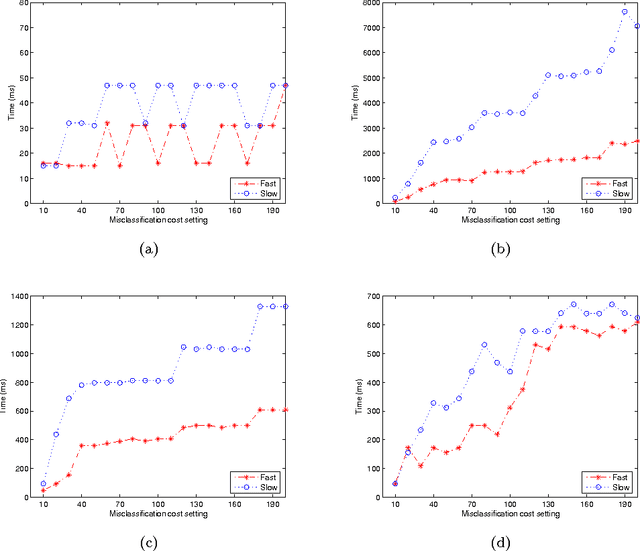
Minimal cost feature selection is devoted to obtain a trade-off between test costs and misclassification costs. This issue has been addressed recently on nominal data. In this paper, we consider numerical data with measurement errors and study minimal cost feature selection in this model. First, we build a data model with normal distribution measurement errors. Second, the neighborhood of each data item is constructed through the confidence interval. Comparing with discretized intervals, neighborhoods are more reasonable to maintain the information of data. Third, we define a new minimal total cost feature selection problem through considering the trade-off between test costs and misclassification costs. Fourth, we proposed a backtracking algorithm with three effective pruning techniques to deal with this problem. The algorithm is tested on four UCI data sets. Experimental results indicate that the pruning techniques are effective, and the algorithm is efficient for data sets with nearly one thousand objects.