 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGCT: Mutual-Guided Cross-Modality Transformer for Survival Outcome Prediction using Integrative Histopathology-Genomic Features
Paper and Code
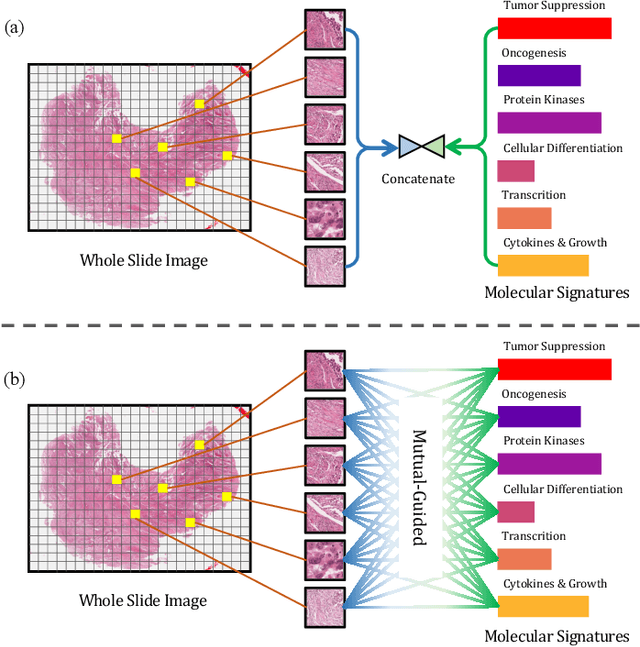
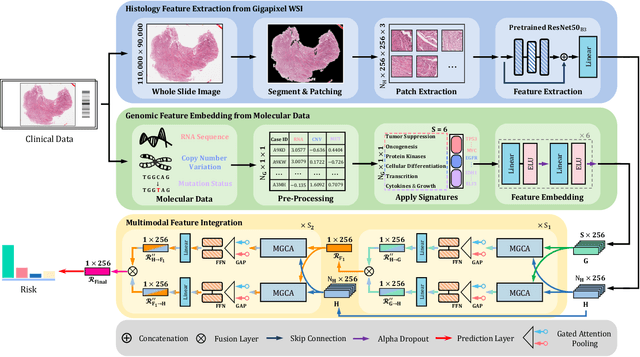
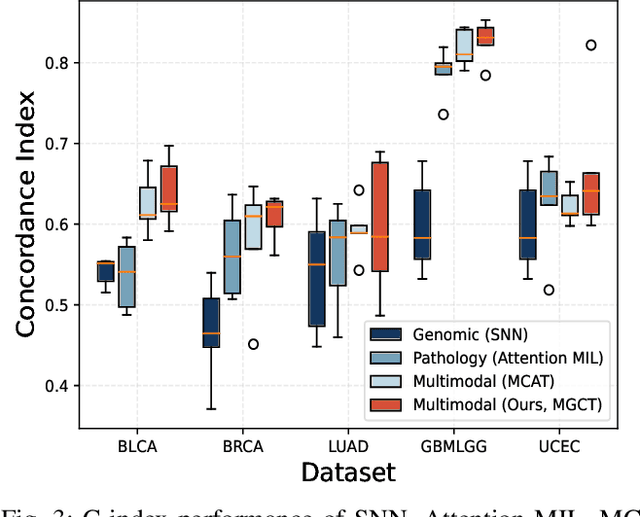
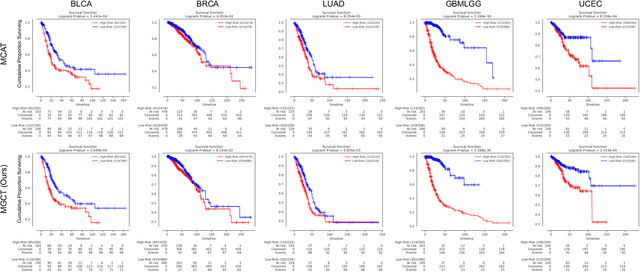
The rapidly emerging field of deep learning-based computational pathology has shown promising results in utilizing whole slide images (WSIs) to objectively prognosticate cancer patients. However, most prognostic methods are currently limited to either histopathology or genomics alone, which inevitably reduces their potential to accurately predict patient prognosis. Whereas integrating WSIs and genomic features presents three main challenges: (1) the enormous heterogeneity of gigapixel WSIs which can reach sizes as large as 150,000x150,000 pixels; (2) the absence of a spatially corresponding relationship between histopathology images and genomic molecular data; and (3) the existing early, late, and intermediate multimodal feature fusion strategies struggle to capture the explicit interactions between WSIs and genomics. To ameliorate these issues, we propose the Mutual-Guided Cross-Modality Transformer (MGCT), a weakly-supervised, attention-based multimodal learning framework that can combine histology features and genomic features to model the genotype-phenotype interactions within the tumor microenvironment. To validate the effectiveness of MGCT, we conduct experiments using nearly 3,600 gigapixel WSIs across five different cancer types sourced from The Cancer Genome Atlas (TCGA). Extensive experimental results consistently emphasize that MGCT outperforms the state-of-the-art (SOTA) methods.