 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetrology for AI: From Benchmarks to Instruments
Paper and Code
Nov 05, 2019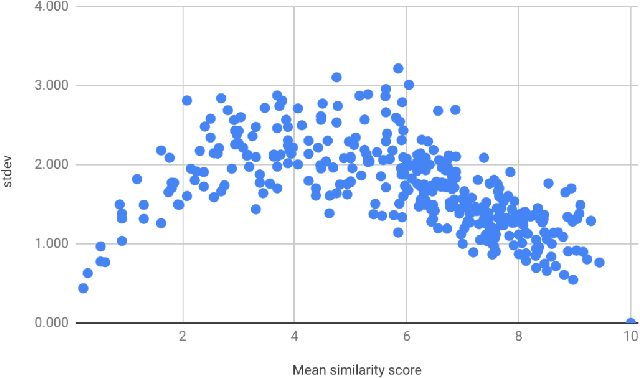
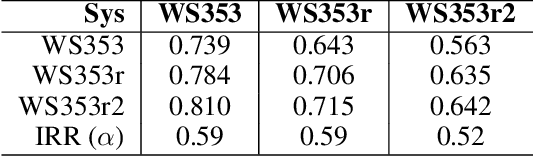

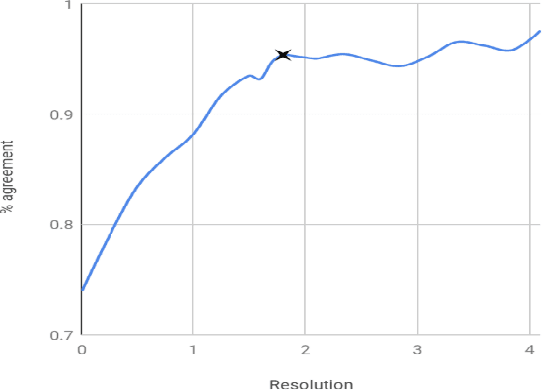
In this paper we present the first steps towards hardening the science of measuring AI systems, by adopting metrology, the science of measurement and its application, and applying it to human (crowd) powered evaluations. We begin with the intuitive observation that evaluating the performance of an AI system is a form of measurement. In all other science and engineering disciplines, the devices used to measure are called instruments, and all measurements are recorded with respect to the characteristics of the instruments used. One does not report mass, speed, or length, for example, of a studied object without disclosing the precision (measurement variance) and resolution (smallest detectable change) of the instrument used. It is extremely common in the AI literature to compare the performance of two systems by using a crowd-sourced dataset as an instrument, but failing to report if the performance difference lies within the capability of that instrument to measure. To illustrate the adoption of metrology to benchmark datasets we use the word similarity benchmark WS353 and several previously published experiments that use it for evaluation.