 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric-Optimized Example Weights
Paper and Code
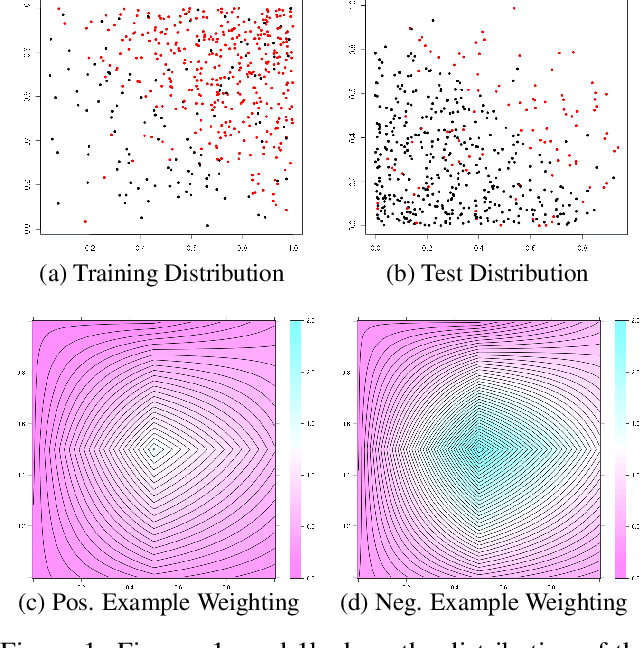
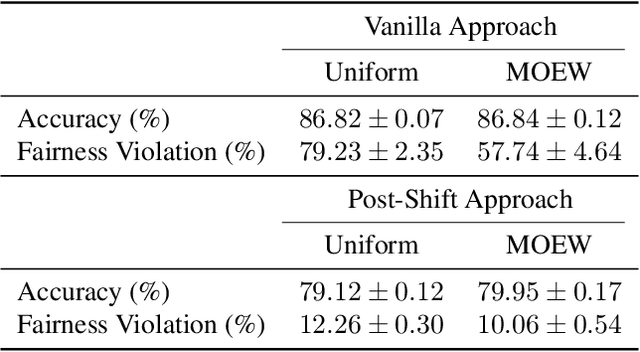
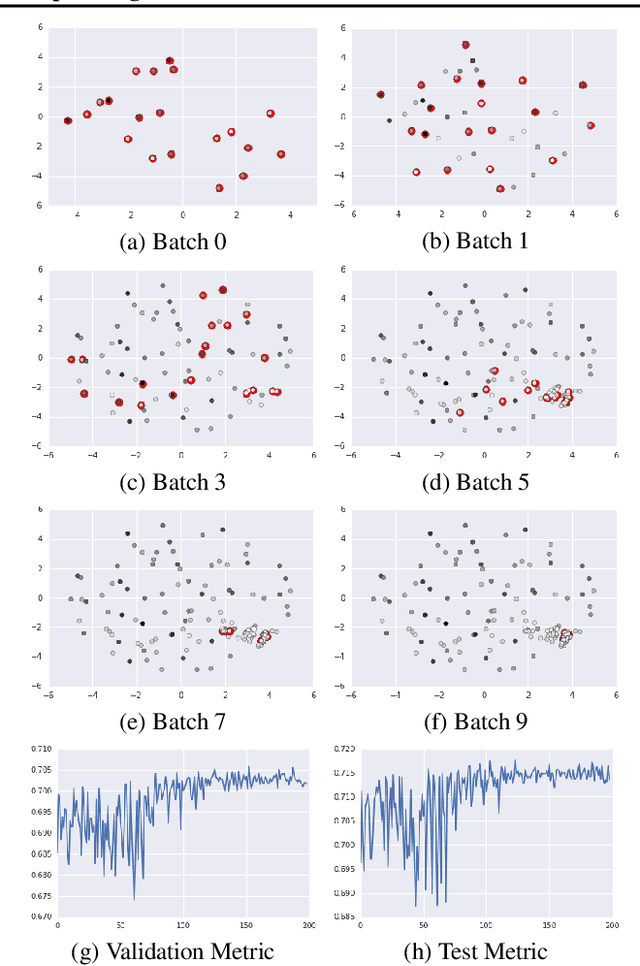
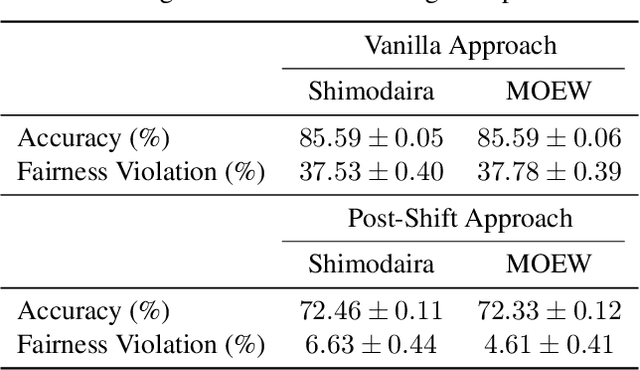
Real-world machine learning applications often have complex test metrics, and may have training and test data that follow different distributions. We propose addressing these issues by using a weighted loss function with a standard convex loss, but with weights on the training examples that are learned to optimize the test metric of interest on the validation set. These metric-optimized example weights can be learned for any test metric, including black box losses and customized metrics for specific applications. We illustrate the performance of our proposal with public benchmark datasets and real-world applications with domain shift and custom loss functions that balance multiple objectives, impose fairness policies, and are non-convex and non-decomposable.