 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric learning pairwise kernel for graph inference
Paper and Code
Oct 21, 2006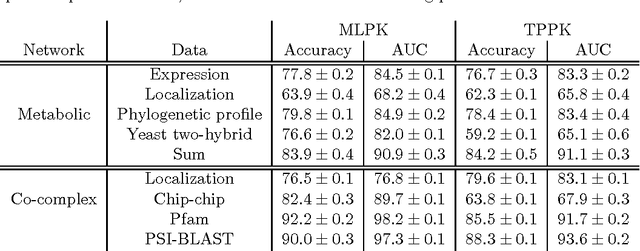
Much recent work in bioinformatics has focused on the inference of various types of biological networks, representing gene regulation, metabolic processes, protein-protein interactions, etc. A common setting involves inferring network edges in a supervised fashion from a set of high-confidence edges, possibly characterized by multiple, heterogeneous data sets (protein sequence, gene expression, etc.). Here, we distinguish between two modes of inference in this setting: direct inference based upon similarities between nodes joined by an edge, and indirect inference based upon similarities between one pair of nodes and another pair of nodes. We propose a supervised approach for the direct case by translating it into a distance metric learning problem. A relaxation of the resulting convex optimization problem leads to the support vector machine (SVM) algorithm with a particular kernel for pairs, which we call the metric learning pairwise kernel (MLPK). We demonstrate, using several real biological networks, that this direct approach often improves upon the state-of-the-art SVM for indirect inference with the tensor product pairwise kernel.