 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Reinforcement Learning by Tracking Task Non-stationarity
Paper and Code
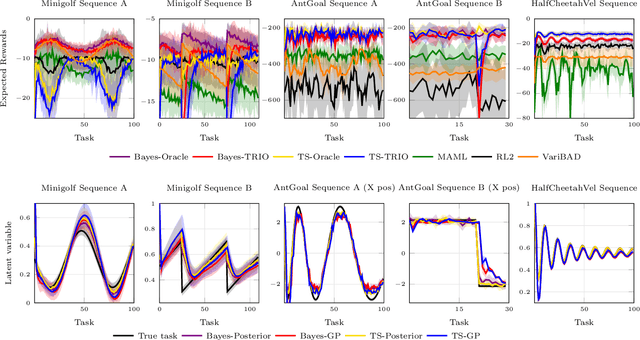



Many real-world domains are subject to a structured non-stationarity which affects the agent's goals and the environmental dynamics. Meta-reinforcement learning (RL) has been shown successful for training agents that quickly adapt to related tasks. However, most of the existing meta-RL algorithms for non-stationary domains either make strong assumptions on the task generation process or require sampling from it at training time. In this paper, we propose a novel algorithm (TRIO) that optimizes for the future by explicitly tracking the task evolution through time. At training time, TRIO learns a variational module to quickly identify latent parameters from experience samples. This module is learned jointly with an optimal exploration policy that takes task uncertainty into account. At test time, TRIO tracks the evolution of the latent parameters online, hence reducing the uncertainty over future tasks and obtaining fast adaptation through the meta-learned policy. Unlike most existing methods, TRIO does not assume Markovian task-evolution processes, it does not require information about the non-stationarity at training time, and it captures complex changes undergoing in the environment. We evaluate our algorithm on different simulated problems and show it outperforms competitive baselines.