 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning Transferable Representations with a Single Target Domain
Paper and Code
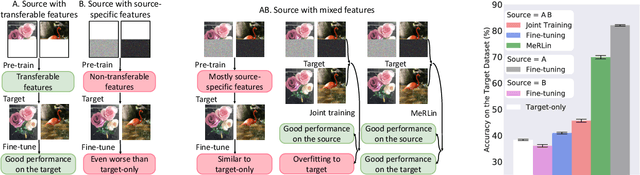
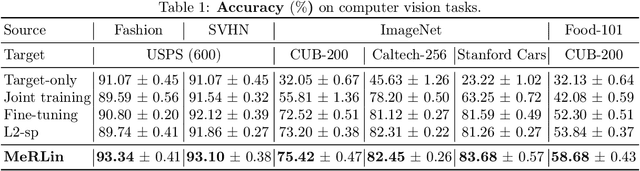


Recent works found that fine-tuning and joint training---two popular approaches for transfer learning---do not always improve accuracy on downstream tasks. First, we aim to understand more about when and why fine-tuning and joint training can be suboptimal or even harmful for transfer learning. We design semi-synthetic datasets where the source task can be solved by either source-specific features or transferable features. We observe that (1) pre-training may not have incentive to learn transferable features and (2) joint training may simultaneously learn source-specific features and overfit to the target. Second, to improve over fine-tuning and joint training, we propose Meta Representation Learning (MeRLin) to learn transferable features. MeRLin meta-learns representations by ensuring that a head fit on top of the representations with target training data also performs well on target validation data. We also prove that MeRLin recovers the target ground-truth model with a quadratic neural net parameterization and a source distribution that contains both transferable and source-specific features. On the same distribution, pre-training and joint training provably fail to learn transferable features. MeRLin empirically outperforms previous state-of-the-art transfer learning algorithms on various real-world vision and NLP transfer learning benchmarks.