 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Learning for Code Summarization
Paper and Code

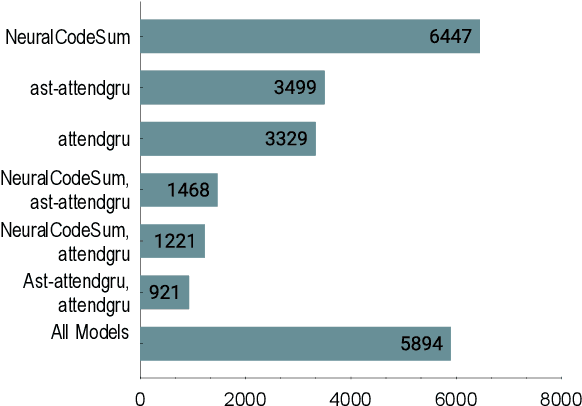
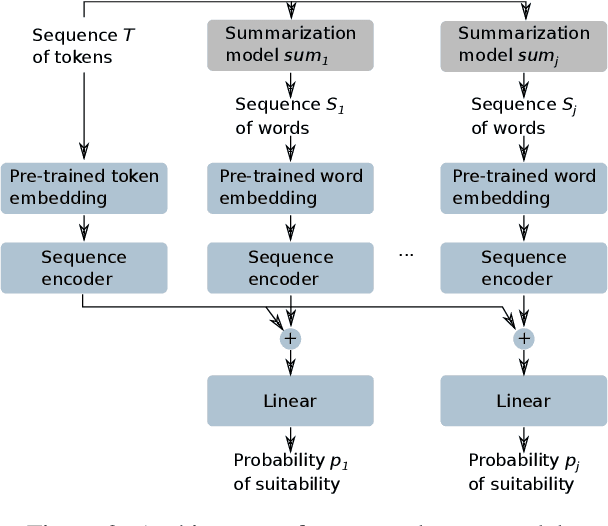
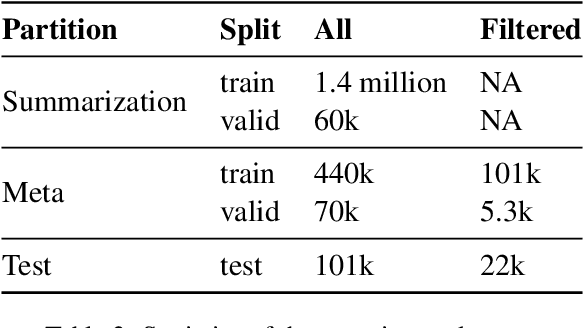
Source code summarization is the task of generating a high-level natural language description for a segment of programming language code. Current neural models for the task differ in their architecture and the aspects of code they consider. In this paper, we show that three SOTA models for code summarization work well on largely disjoint subsets of a large code-base. This complementarity motivates model combination: We propose three meta-models that select the best candidate summary for a given code segment. The two neural models improve significantly over the performance of the best individual model, obtaining an improvement of 2.1 BLEU points on a dataset of code segments where at least one of the individual models obtains a non-zero BLEU.