 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Dialogue Policy Learning
Paper and Code
Jun 03, 2020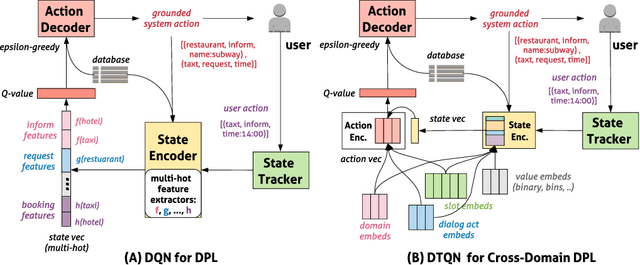
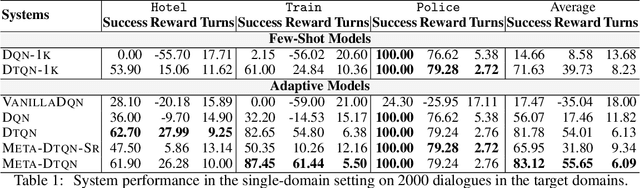
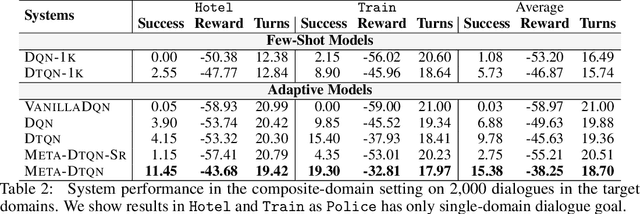
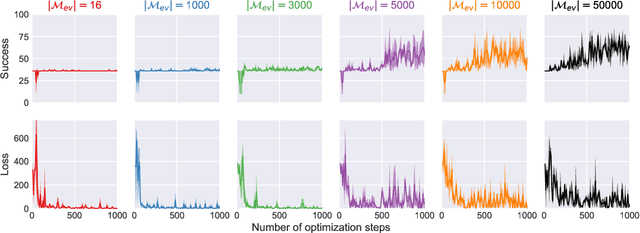
Dialog policy determines the next-step actions for agents and hence is central to a dialogue system. However, when migrated to novel domains with little data, a policy model can fail to adapt due to insufficient interactions with the new environment. We propose Deep Transferable Q-Network (DTQN) to utilize shareable low-level signals between domains, such as dialogue acts and slots. We decompose the state and action representation space into feature subspaces corresponding to these low-level components to facilitate cross-domain knowledge transfer. Furthermore, we embed DTQN in a meta-learning framework and introduce Meta-DTQN with a dual-replay mechanism to enable effective off-policy training and adaptation. In experiments, our model outperforms baseline models in terms of both success rate and dialogue efficiency on the multi-domain dialogue dataset MultiWOZ 2.0.