Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMessage Passing Attention Networks for Document Understanding
Paper and Code
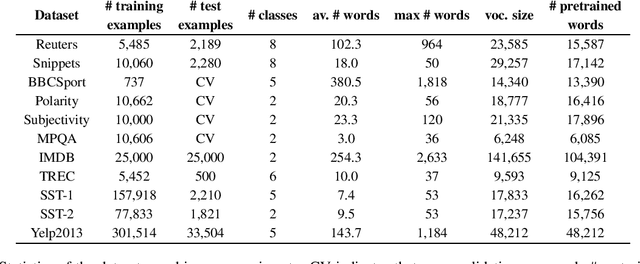
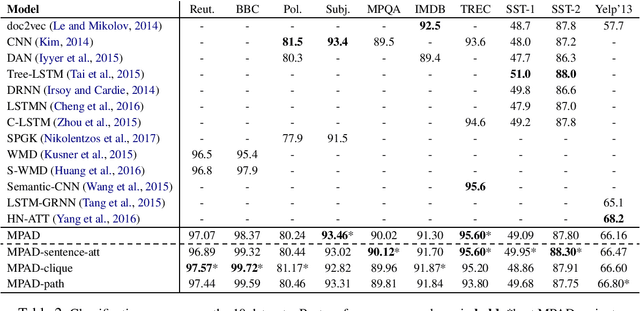
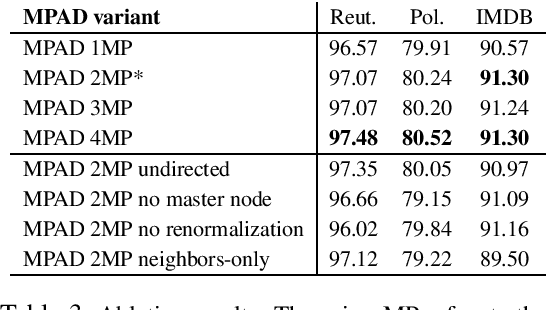
Most graph neural networks can be described in terms of message passing, vertex update, and readout functions. In this paper, we represent documents as word co-occurrence networks and propose an application of the message passing framework to NLP, the Message Passing Attention network for Document understanding (MPAD). We also propose several hierarchical variants of MPAD. Experiments conducted on 10 standard text classification datasets show that our architectures are competitive with the state-of-the-art. Ablation studies reveal further insights about the impact of the different components on performance. Code and data are publicly available.
* An early version of this paper was submitted to EMNLP 2018
View paper on