 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEmoBERT: Pre-training Model with Prompt-based Learning for Multimodal Emotion Recognition
Paper and Code
Oct 27, 2021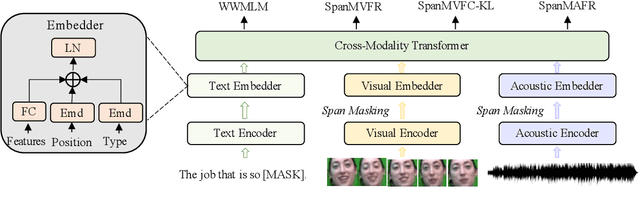

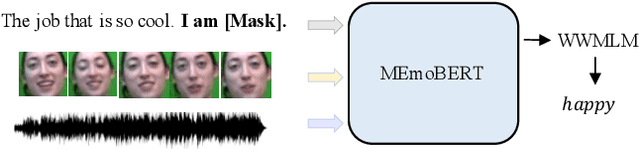
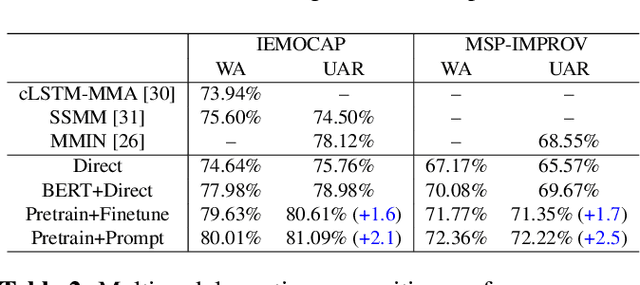
Multimodal emotion recognition study is hindered by the lack of labelled corpora in terms of scale and diversity, due to the high annotation cost and label ambiguity. In this paper, we propose a pre-training model \textbf{MEmoBERT} for multimodal emotion recognition, which learns multimodal joint representations through self-supervised learning from large-scale unlabeled video data that come in sheer volume. Furthermore, unlike the conventional "pre-train, finetune" paradigm, we propose a prompt-based method that reformulates the downstream emotion classification task as a masked text prediction one, bringing the downstream task closer to the pre-training. Extensive experiments on two benchmark datasets, IEMOCAP and MSP-IMPROV, show that our proposed MEmoBERT significantly enhances emotion recognition performance.