 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks and Defenses in Supervised Learning via Generalization Gap
Paper and Code
Feb 27, 2020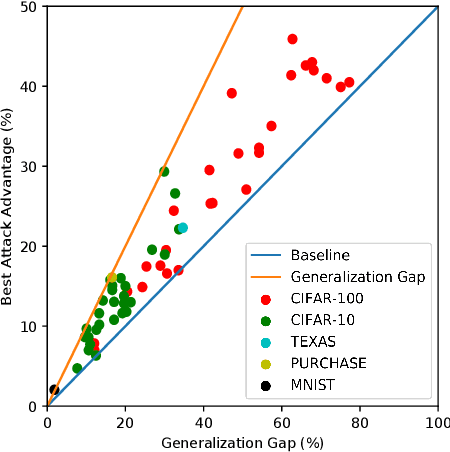

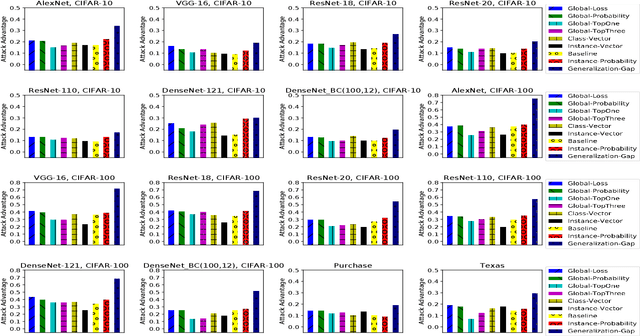
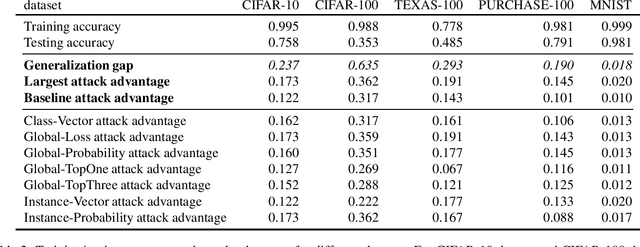
This work studies membership inference (MI) attack against classifiers, where the attacker's goal is to determine whether a data instance was used for training the classifier. While it is known that overfitting makes classifiers susceptible to MI attacks, we showcase a simple numerical relationship between the generalization gap---the difference between training and test accuracies---and the classifier's vulnerability to MI attacks---as measured by an MI attack's accuracy gain over a random guess. We then propose to close the gap by matching the training and validation accuracies during training, by means of a new {\em set regularizer} using the Maximum Mean Discrepancy between the softmax output empirical distributions of the training and validation sets. Our experimental results show that combining this approach with another simple defense (mix-up training) significantly improves state-of-the-art defense against MI attacks, with minimal impact on testing accuracy.