 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeLIME: Meaningful Local Explanation for Machine Learning Models
Paper and Code
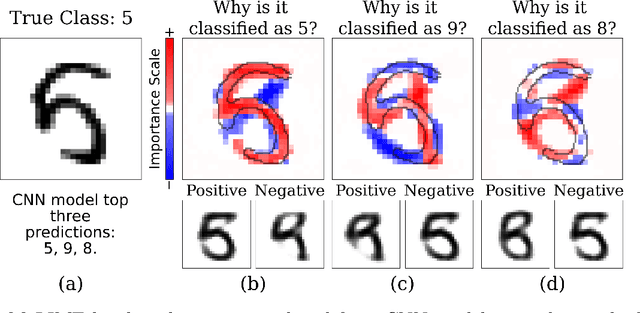

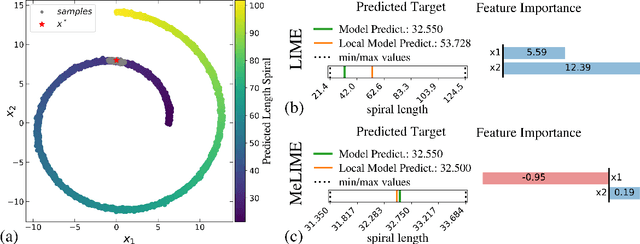
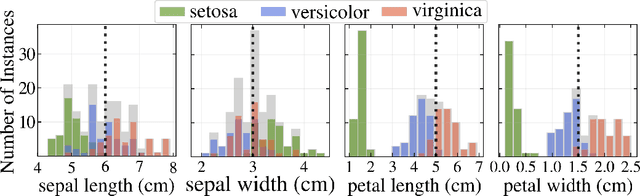
Most state-of-the-art machine learning algorithms induce black-box models, preventing their application in many sensitive domains. Hence, many methodologies for explaining machine learning models have been proposed to address this problem. In this work, we introduce strategies to improve local explanations taking into account the distribution of the data used to train the black-box models. We show that our approach, MeLIME, produces more meaningful explanations compared to other techniques over different ML models, operating on various types of data. MeLIME generalizes the LIME method, allowing more flexible perturbation sampling and the use of different local interpretable models. Additionally, we introduce modifications to standard training algorithms of local interpretable models fostering more robust explanations, even allowing the production of counterfactual examples. To show the strengths of the proposed approach, we include experiments on tabular data, images, and text; all showing improved explanations. In particular, MeLIME generated more meaningful explanations on the MNIST dataset than methods such as GuidedBackprop, SmoothGrad, and Layer-wise Relevance Propagation. MeLIME is available on https://github.com/tiagobotari/melime.