 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Image Deidentification, Cleaning and Compression Using Pylogik
Paper and Code
May 03, 2023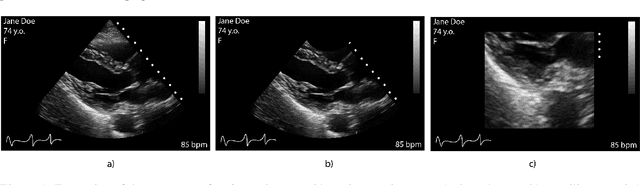

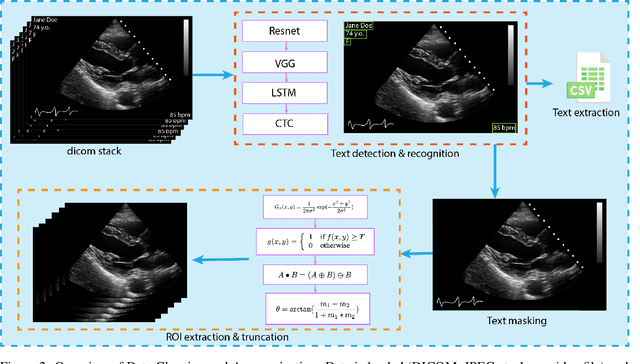
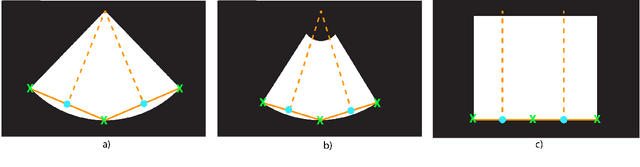
Leveraging medical record information in the era of big data and machine learning comes with the caveat that data must be cleaned and deidentified. Facilitating data sharing and harmonization for multi-center collaborations are particularly difficult when protected health information (PHI) is contained or embedded in image meta-data. We propose a novel library in the Python framework, called PyLogik, to help alleviate this issue for ultrasound images, which are particularly challenging because of the frequent inclusion of PHI directly on the images. PyLogik processes the image volumes through a series of text detection/extraction, filtering, thresholding, morphological and contour comparisons. This methodology deidentifies the images, reduces file sizes, and prepares image volumes for applications in deep learning and data sharing. To evaluate its effectiveness in the identification of regions of interest (ROI), a random sample of 50 cardiac ultrasounds (echocardiograms) were processed through PyLogik, and the outputs were compared with the manual segmentations by an expert user. The Dice coefficient of the two approaches achieved an average value of 0.976. Next, an investigation was conducted to ascertain the degree of information compression achieved using the algorithm. Resultant data was found to be on average approximately 72% smaller after processing by PyLogik. Our results suggest that PyLogik is a viable methodology for ultrasound data cleaning and deidentification, determining ROI, and file compression which will facilitate efficient storage, use, and dissemination of ultrasound data.