 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMax-Margin Token Selection in Attention Mechanism
Paper and Code
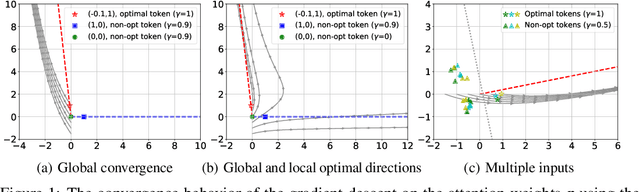
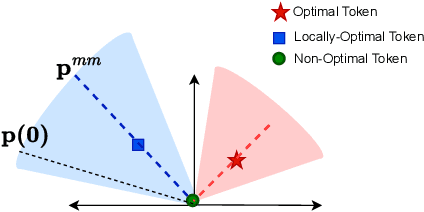
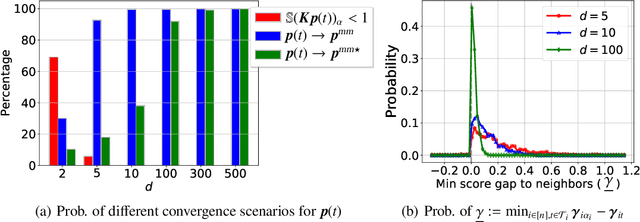
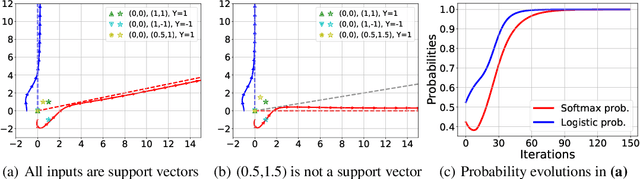
Attention mechanism is a central component of the transformer architecture which led to the phenomenal success of large language models. However, the theoretical principles underlying the attention mechanism are poorly understood, especially its nonconvex optimization dynamics. In this work, we explore the seminal softmax-attention model $f(\boldsymbol{X})=\langle \boldsymbol{Xv}, \texttt{softmax}(\boldsymbol{XWp})\rangle$, where $\boldsymbol{X}$ is the token sequence and $(\boldsymbol{v},\boldsymbol{W},\boldsymbol{p})$ are trainable parameters. We prove that running gradient descent on $\boldsymbol{p}$, or equivalently $\boldsymbol{W}$, converges in direction to a max-margin solution that separates $\textit{locally-optimal}$ tokens from non-optimal ones. This clearly formalizes attention as an optimal token selection mechanism. Remarkably, our results are applicable to general data and precisely characterize $\textit{optimality}$ of tokens in terms of the value embeddings $\boldsymbol{Xv}$ and problem geometry. We also provide a broader regularization path analysis that establishes the margin maximizing nature of attention even for nonlinear prediction heads. When optimizing $\boldsymbol{v}$ and $\boldsymbol{p}$ simultaneously with logistic loss, we identify conditions under which the regularization paths directionally converge to their respective hard-margin SVM solutions where $\boldsymbol{v}$ separates the input features based on their labels. Interestingly, the SVM formulation of $\boldsymbol{p}$ is influenced by the support vector geometry of $\boldsymbol{v}$. Finally, we verify our theoretical findings via numerical experiments and provide insights.