Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively Multilingual Word Embeddings
Paper and Code
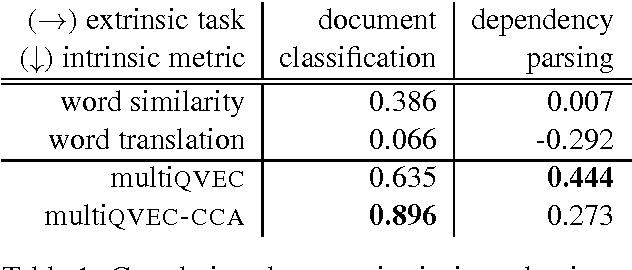
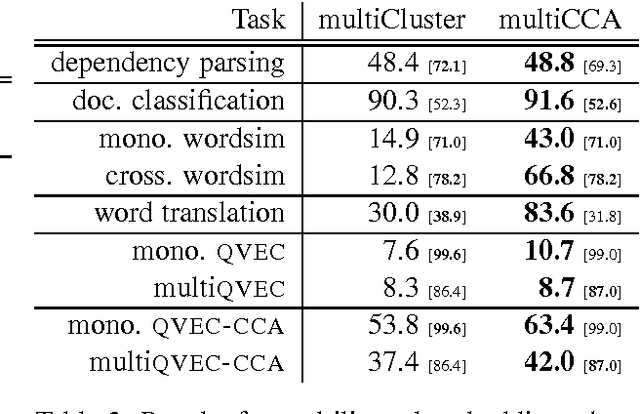
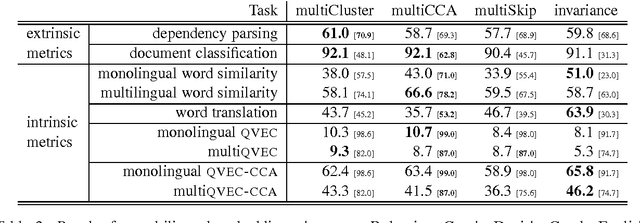
We introduce new methods for estimating and evaluating embeddings of words in more than fifty languages in a single shared embedding space. Our estimation methods, multiCluster and multiCCA, use dictionaries and monolingual data; they do not require parallel data. Our new evaluation method, multiQVEC-CCA, is shown to correlate better than previous ones with two downstream tasks (text categorization and parsing). We also describe a web portal for evaluation that will facilitate further research in this area, along with open-source releases of all our methods.
View paper on