 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Autoencoders are Robust Data Augmentors
Paper and Code
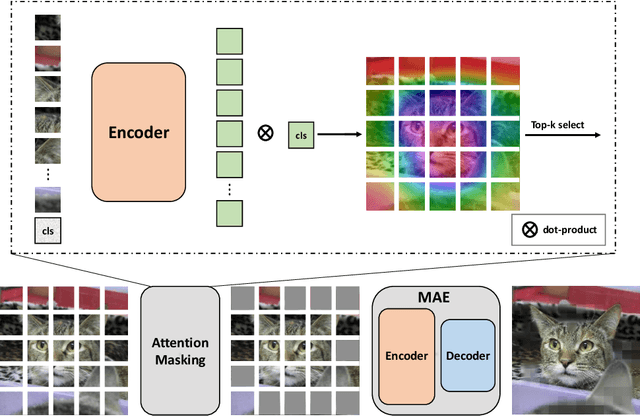
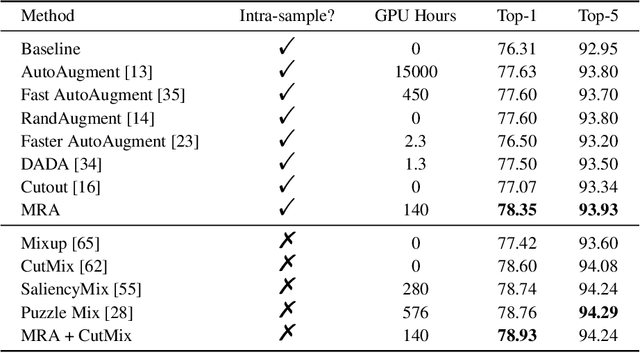


Deep neural networks are capable of learning powerful representations to tackle complex vision tasks but expose undesirable properties like the over-fitting issue. To this end, regularization techniques like image augmentation are necessary for deep neural networks to generalize well. Nevertheless, most prevalent image augmentation recipes confine themselves to off-the-shelf linear transformations like scale, flip, and colorjitter. Due to their hand-crafted property, these augmentations are insufficient to generate truly hard augmented examples. In this paper, we propose a novel perspective of augmentation to regularize the training process. Inspired by the recent success of applying masked image modeling to self-supervised learning, we adopt the self-supervised masked autoencoder to generate the distorted view of the input images. We show that utilizing such model-based nonlinear transformation as data augmentation can improve high-level recognition tasks. We term the proposed method as \textbf{M}ask-\textbf{R}econstruct \textbf{A}ugmentation (MRA). The extensive experiments on various image classification benchmarks verify the effectiveness of the proposed augmentation. Specifically, MRA consistently enhances the performance on supervised, semi-supervised as well as few-shot classification. The code will be available at \url{https://github.com/haohang96/MRA}.