 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Auto-context Decision Forests to Deep ConvNets for Semantic Segmentation
Paper and Code


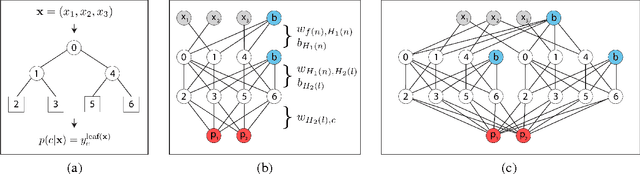
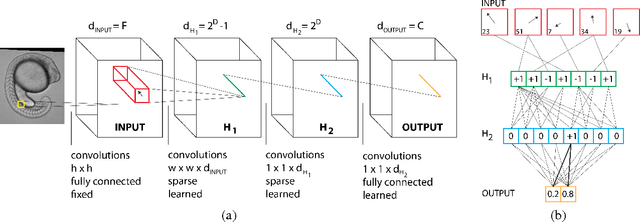
We consider the task of pixel-wise semantic segmentation given a small set of labeled training images. Among two of the most popular techniques to address this task are Decision Forests (DF) and Neural Networks (NN). In this work, we explore the relationship between two special forms of these techniques: stacked DFs (namely Auto-context) and deep Convolutional Neural Networks (ConvNet). Our main contribution is to show that Auto-context can be mapped to a deep ConvNet with novel architecture, and thereby trained end-to-end. This mapping can be used as an initialization of a deep ConvNet, enabling training even in the face of very limited amounts of training data. We also demonstrate an approximate mapping back from the refined ConvNet to a second stacked DF, with improved performance over the original. We experimentally verify that these mappings outperform stacked DFs for two different applications in computer vision and biology: Kinect-based body part labeling from depth images, and somite segmentation in microscopy images of developing zebrafish. Finally, we revisit the core mapping from a Decision Tree (DT) to a NN, and show that it is also possible to map a fuzzy DT, with sigmoidal split decisions, to a NN. This addresses multiple limitations of the previous mapping, and yields new insights into the popular Rectified Linear Unit (ReLU), and more recently proposed concatenated ReLU (CReLU), activation functions.