 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Risk Minimization Tolerant to Label Noise
Paper and Code
Sep 10, 2015

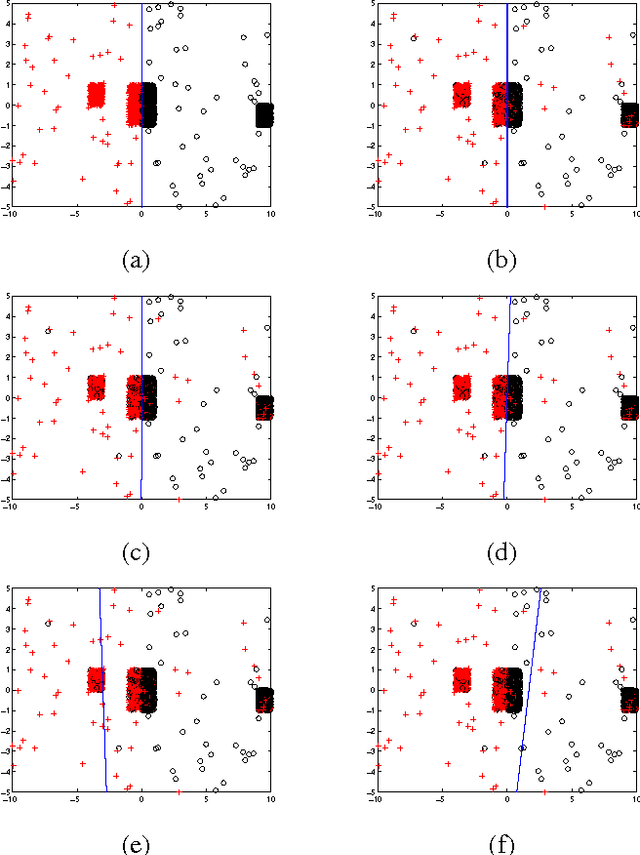

In many applications, the training data, from which one needs to learn a classifier, is corrupted with label noise. Many standard algorithms such as SVM perform poorly in presence of label noise. In this paper we investigate the robustness of risk minimization to label noise. We prove a sufficient condition on a loss function for the risk minimization under that loss to be tolerant to uniform label noise. We show that the $0-1$ loss, sigmoid loss, ramp loss and probit loss satisfy this condition though none of the standard convex loss functions satisfy it. We also prove that, by choosing a sufficiently large value of a parameter in the loss function, the sigmoid loss, ramp loss and probit loss can be made tolerant to non-uniform label noise also if we can assume the classes to be separable under noise-free data distribution. Through extensive empirical studies, we show that risk minimization under the $0-1$ loss, the sigmoid loss and the ramp loss has much better robustness to label noise when compared to the SVM algorithm.