Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Learners (More) Monotone
Paper and Code
Nov 25, 2019
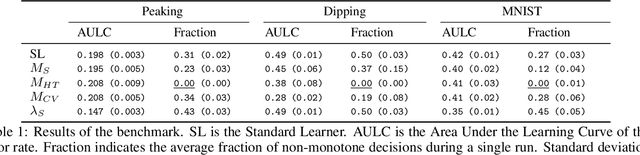
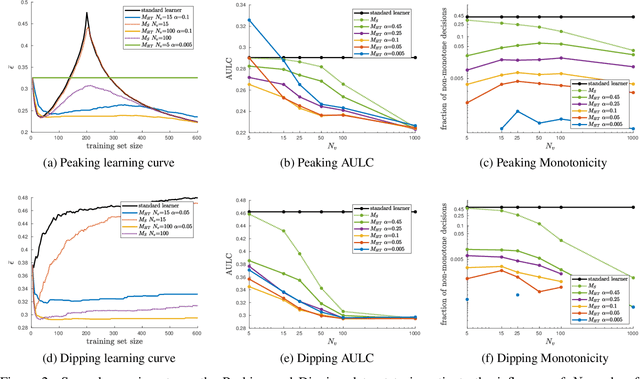

Learning performance can show non-monotonic behavior. That is, more data does not necessarily lead to better models, even on average. We propose three algorithms that take a supervised learning model and make it perform more monotone. We prove consistency and monotonicity with high probability, and evaluate the algorithms on scenarios where non-monotone behaviour occurs. Our proposed algorithm $\text{MT}_{\text{HT}}$ makes less than $1\%$ non-monotone decisions on MNIST while staying competitive in terms of error rate compared to several baselines.
View paper on