 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaIL: A Unified Mask-Image-Language Trimodal Network for Referring Image Segmentation
Paper and Code
Nov 25, 2021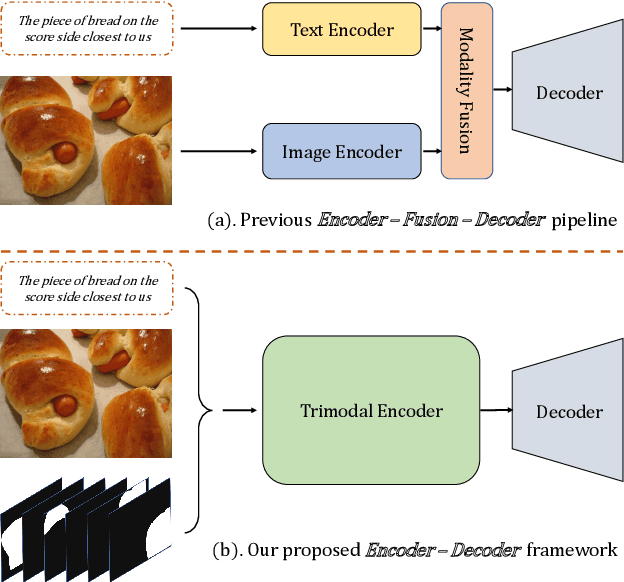



Referring image segmentation is a typical multi-modal task, which aims at generating a binary mask for referent described in given language expressions. Prior arts adopt a bimodal solution, taking images and languages as two modalities within an encoder-fusion-decoder pipeline. However, this pipeline is sub-optimal for the target task for two reasons. First, they only fuse high-level features produced by uni-modal encoders separately, which hinders sufficient cross-modal learning. Second, the uni-modal encoders are pre-trained independently, which brings inconsistency between pre-trained uni-modal tasks and the target multi-modal task. Besides, this pipeline often ignores or makes little use of intuitively beneficial instance-level features. To relieve these problems, we propose MaIL, which is a more concise encoder-decoder pipeline with a Mask-Image-Language trimodal encoder. Specifically, MaIL unifies uni-modal feature extractors and their fusion model into a deep modality interaction encoder, facilitating sufficient feature interaction across different modalities. Meanwhile, MaIL directly avoids the second limitation since no uni-modal encoders are needed anymore. Moreover, for the first time, we propose to introduce instance masks as an additional modality, which explicitly intensifies instance-level features and promotes finer segmentation results. The proposed MaIL set a new state-of-the-art on all frequently-used referring image segmentation datasets, including RefCOCO, RefCOCO+, and G-Ref, with significant gains, 3%-10% against previous best methods. Code will be released soon.