 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAFNet: A Multi-Attention Fusion Network for RGB-T Crowd Counting
Paper and Code
Aug 14, 2022
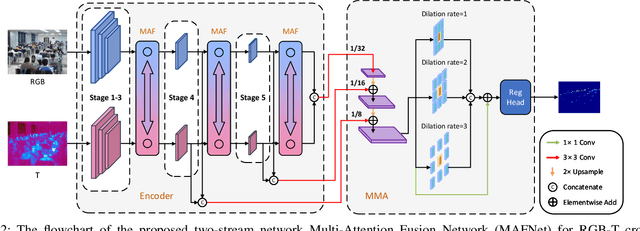
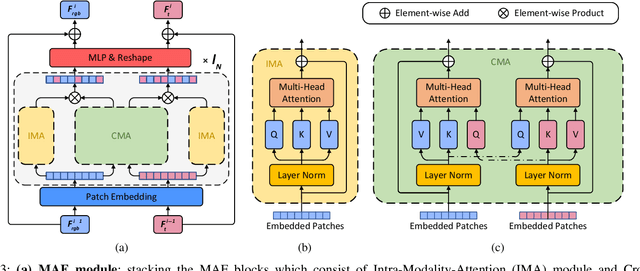

RGB-Thermal (RGB-T) crowd counting is a challenging task, which uses thermal images as complementary information to RGB images to deal with the decreased performance of unimodal RGB-based methods in scenes with low-illumination or similar backgrounds. Most existing methods propose well-designed structures for cross-modal fusion in RGB-T crowd counting. However, these methods have difficulty in encoding cross-modal contextual semantic information in RGB-T image pairs. Considering the aforementioned problem, we propose a two-stream RGB-T crowd counting network called Multi-Attention Fusion Network (MAFNet), which aims to fully capture long-range contextual information from the RGB and thermal modalities based on the attention mechanism. Specifically, in the encoder part, a Multi-Attention Fusion (MAF) module is embedded into different stages of the two modality-specific branches for cross-modal fusion at the global level. In addition, a Multi-modal Multi-scale Aggregation (MMA) regression head is introduced to make full use of the multi-scale and contextual information across modalities to generate high-quality crowd density maps. Extensive experiments on two popular datasets show that the proposed MAFNet is effective for RGB-T crowd counting and achieves the state-of-the-art performance.