 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPF: A Language-Prior Feedback Objective Function for De-biased Visual Question Answering
Paper and Code
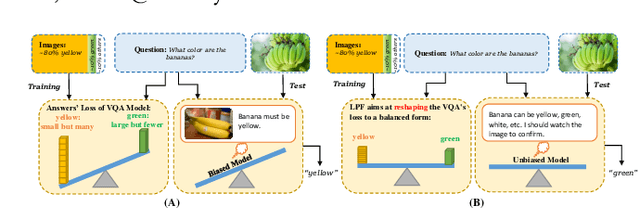
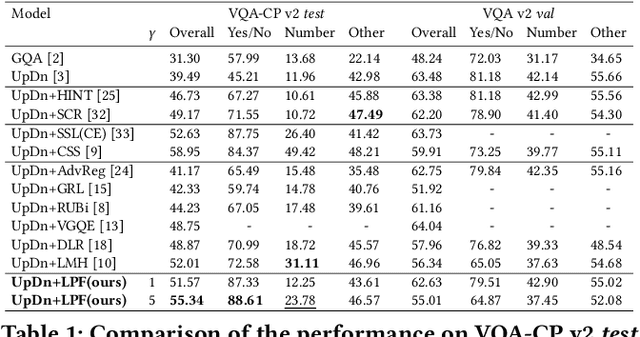
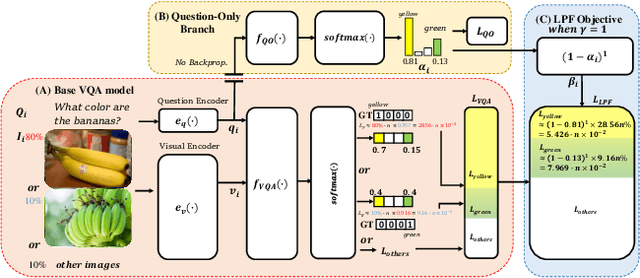
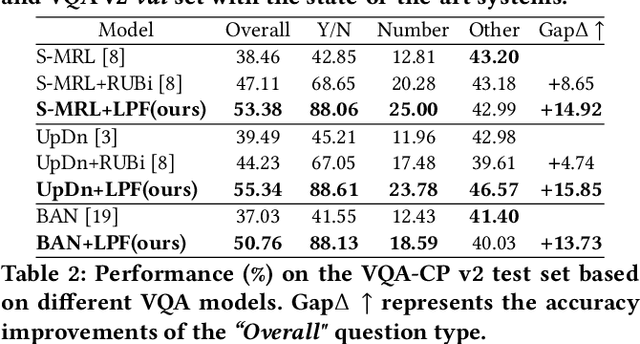
Most existing Visual Question Answering (VQA) systems tend to overly rely on language bias and hence fail to reason from the visual clue. To address this issue, we propose a novel Language-Prior Feedback (LPF) objective function, to re-balance the proportion of each answer's loss value in the total VQA loss. The LPF firstly calculates a modulating factor to determine the language bias using a question-only branch. Then, the LPF assigns a self-adaptive weight to each training sample in the training process. With this reweighting mechanism, the LPF ensures that the total VQA loss can be reshaped to a more balanced form. By this means, the samples that require certain visual information to predict will be efficiently used during training. Our method is simple to implement, model-agnostic, and end-to-end trainable. We conduct extensive experiments and the results show that the LPF (1) brings a significant improvement over various VQA models, (2) achieves competitive performance on the bias-sensitive VQA-CP v2 benchmark.