 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLosing Visual Needles in Image Haystacks: Vision Language Models are Easily Distracted in Short and Long Contexts
Paper and Code
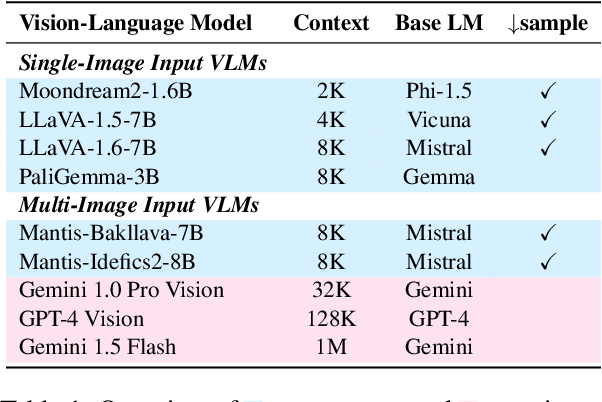

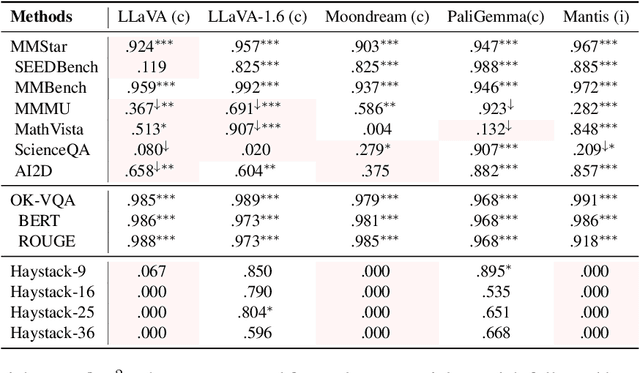
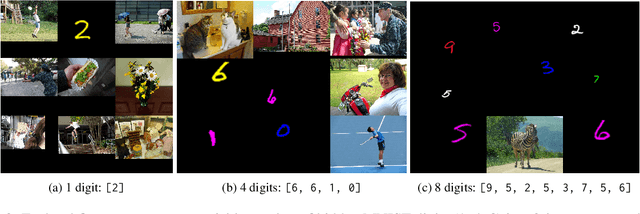
We present LoCoVQA, a dynamic benchmark generator for evaluating long-context extractive reasoning in vision language models (VLMs). LoCoVQA augments test examples for mathematical reasoning, VQA, and character recognition tasks with increasingly long visual contexts composed of both in-distribution and out-of-distribution distractor images. Across these tasks, a diverse set of VLMs rapidly lose performance as the visual context length grows, often exhibiting a striking exponential decay trend. This test assesses how well VLMs can ignore irrelevant information when answering queries -- a task that is quite easy for language models (LMs) in the text domain -- demonstrating that current state-of-the-art VLMs lack this essential capability for many long-context applications.