 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking for the Signs: Identifying Isolated Sign Instances in Continuous Video Footage
Paper and Code
Jul 21, 2021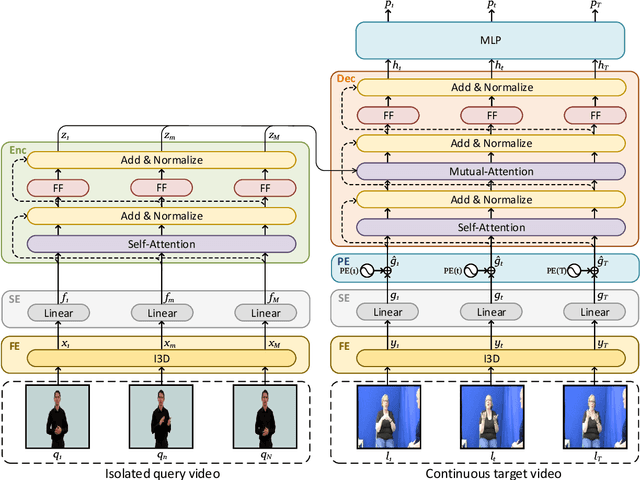

In this paper, we focus on the task of one-shot sign spotting, i.e. given an example of an isolated sign (query), we want to identify whether/where this sign appears in a continuous, co-articulated sign language video (target). To achieve this goal, we propose a transformer-based network, called SignLookup. We employ 3D Convolutional Neural Networks (CNNs) to extract spatio-temporal representations from video clips. To solve the temporal scale discrepancies between the query and the target videos, we construct multiple queries from a single video clip using different frame-level strides. Self-attention is applied across these query clips to simulate a continuous scale space. We also utilize another self-attention module on the target video to learn the contextual within the sequence. Finally a mutual-attention is used to match the temporal scales to localize the query within the target sequence. Extensive experiments demonstrate that the proposed approach can not only reliably identify isolated signs in continuous videos, regardless of the signers' appearance, but can also generalize to different sign languages. By taking advantage of the attention mechanism and the adaptive features, our model achieves state-of-the-art performance on the sign spotting task with accuracy as high as 96% on challenging benchmark datasets and significantly outperforming other approaches.