 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking deeper into interpretable deep learning in neuroimaging: a comprehensive survey
Paper and Code
Jul 14, 2023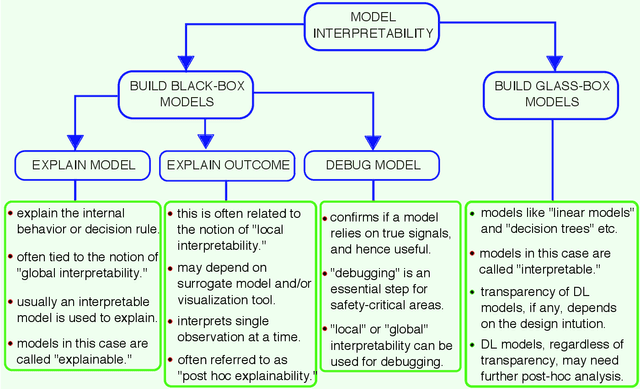
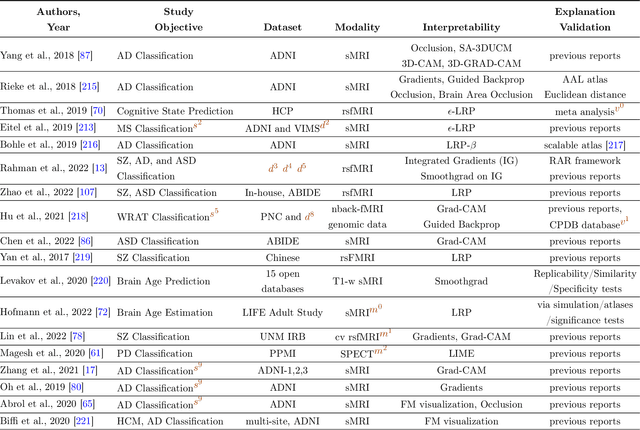
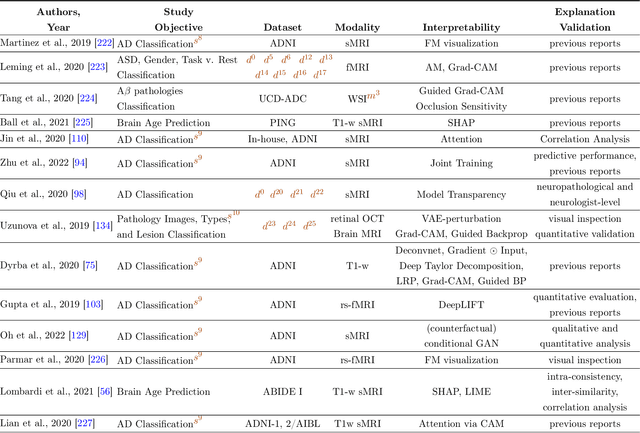
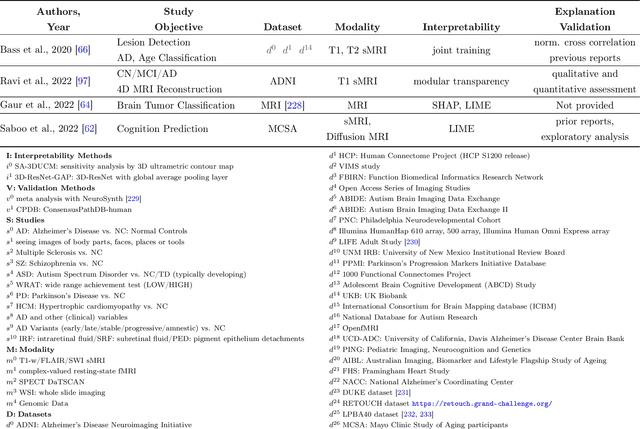
Deep learning (DL) models have been popular due to their ability to learn directly from the raw data in an end-to-end paradigm, alleviating the concern of a separate error-prone feature extraction phase. Recent DL-based neuroimaging studies have also witnessed a noticeable performance advancement over traditional machine learning algorithms. But the challenges of deep learning models still exist because of the lack of transparency in these models for their successful deployment in real-world applications. In recent years, Explainable AI (XAI) has undergone a surge of developments mainly to get intuitions of how the models reached the decisions, which is essential for safety-critical domains such as healthcare, finance, and law enforcement agencies. While the interpretability domain is advancing noticeably, researchers are still unclear about what aspect of model learning a post hoc method reveals and how to validate its reliability. This paper comprehensively reviews interpretable deep learning models in the neuroimaging domain. Firstly, we summarize the current status of interpretability resources in general, focusing on the progression of methods, associated challenges, and opinions. Secondly, we discuss how multiple recent neuroimaging studies leveraged model interpretability to capture anatomical and functional brain alterations most relevant to model predictions. Finally, we discuss the limitations of the current practices and offer some valuable insights and guidance on how we can steer our future research directions to make deep learning models substantially interpretable and thus advance scientific understanding of brain disorders.