 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking at the Overlooked: An Analysis on the Word-Overlap Bias in Natural Language Inference
Paper and Code
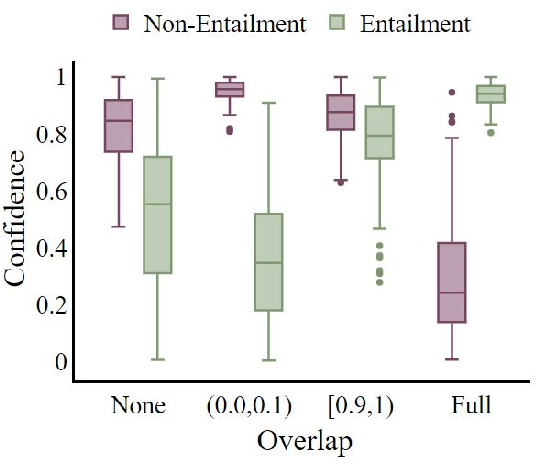

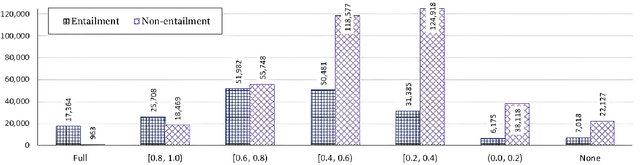
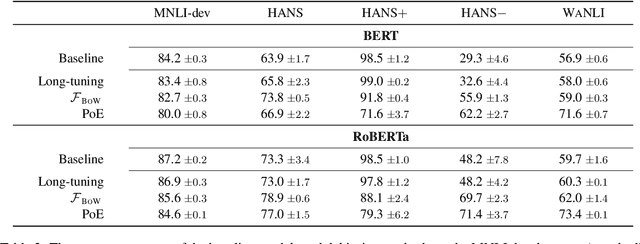
It has been shown that NLI models are usually biased with respect to the word-overlap between premise and hypothesis; they take this feature as a primary cue for predicting the entailment label. In this paper, we focus on an overlooked aspect of the overlap bias in NLI models: the reverse word-overlap bias. Our experimental results demonstrate that current NLI models are highly biased towards the non-entailment label on instances with low overlap, and the existing debiasing methods, which are reportedly successful on existing challenge datasets, are generally ineffective in addressing this category of bias. We investigate the reasons for the emergence of the overlap bias and the role of minority examples in its mitigation. For the former, we find that the word-overlap bias does not stem from pre-training, and for the latter, we observe that in contrast to the accepted assumption, eliminating minority examples does not affect the generalizability of debiasing methods with respect to the overlap bias.