 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing
Paper and Code



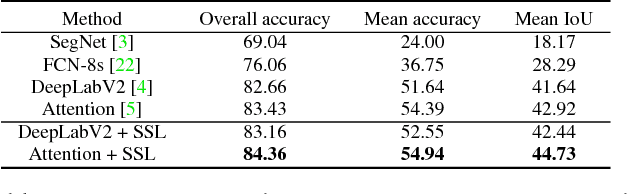
Human parsing has recently attracted a lot of research interests due to its huge application potentials. However existing datasets have limited number of images and annotations, and lack the variety of human appearances and the coverage of challenging cases in unconstrained environment. In this paper, we introduce a new benchmark "Look into Person (LIP)" that makes a significant advance in terms of scalability, diversity and difficulty, a contribution that we feel is crucial for future developments in human-centric analysis. This comprehensive dataset contains over 50,000 elaborately annotated images with 19 semantic part labels, which are captured from a wider range of viewpoints, occlusions and background complexity. Given these rich annotations we perform detailed analyses of the leading human parsing approaches, gaining insights into the success and failures of these methods. Furthermore, in contrast to the existing efforts on improving the feature discriminative capability, we solve human parsing by exploring a novel self-supervised structure-sensitive learning approach, which imposes human pose structures into parsing results without resorting to extra supervision (i.e., no need for specifically labeling human joints in model training). Our self-supervised learning framework can be injected into any advanced neural networks to help incorporate rich high-level knowledge regarding human joints from a global perspective and improve the parsing results. Extensive evaluations on our LIP and the public PASCAL-Person-Part dataset demonstrate the superiority of our method.