 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-tail learning with attributes
Paper and Code

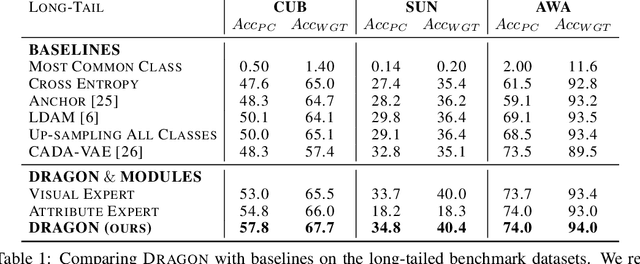
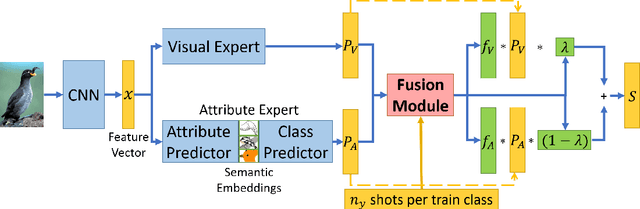
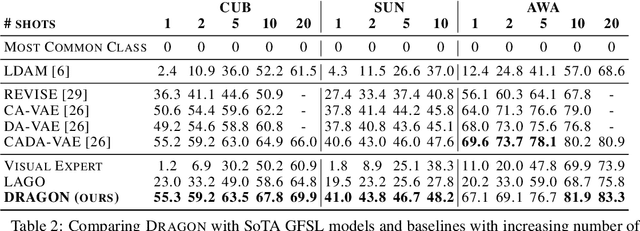
Learning to classify images with unbalanced class distributions is challenged by two effects: It is hard to learn tail classes that have few samples, and it is hard to adapt a single model to both richly-sampled and poorly-sampled classes. To address few-shot learning of tail classes, it is useful to fuse additional information in the form of semantic attributes and classify based on multi-modal information. Unfortunately, as we show below, unbalanced data leads to a "familiarity bias", where classifiers favor sample-rich classes. This bias and lack of calibrated predictions make it hard to fuse correctly information from multiple modalities like vision and attributes. Here we describe DRAGON, a novel modular architecture for long-tail learning designed to address these biases and fuse multi-modal information in face of unbalanced data. Our architecture is based on three classifiers: a vision expert, a semantic attribute expert that excels on the tail classes, and a debias-and-fuse module to combine their predictions. We present the first benchmark for long-tail learning with attributes and use it to evaluate DRAGON. DRAGON outperforms state-of-the-art long-tail learning models and Generalized Few-Shot-Learning with attributes (GFSL-a) models. DRAGON also obtains SoTA in some existing benchmarks for single-modality GFSL.