 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogistic-Normal Likelihoods for Heteroscedastic Label Noise in Classification
Paper and Code



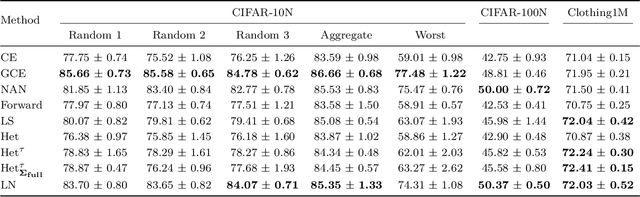
A natural way of estimating heteroscedastic label noise in regression is to model the observed (potentially noisy) target as a sample from a normal distribution, whose parameters can be learned by minimizing the negative log-likelihood. This loss has desirable loss attenuation properties, as it can reduce the contribution of high-error examples. Intuitively, this behavior can improve robustness against label noise by reducing overfitting. We propose an extension of this simple and probabilistic approach to classification that has the same desirable loss attenuation properties. We evaluate the effectiveness of the method by measuring its robustness against label noise in classification. We perform enlightening experiments exploring the inner workings of the method, including sensitivity to hyperparameters, ablation studies, and more.