 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Sparse Networks for Interpretable Predictions
Paper and Code
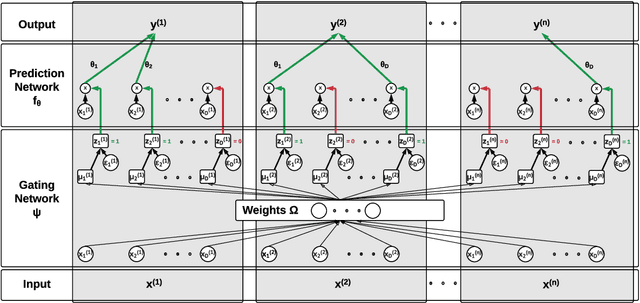
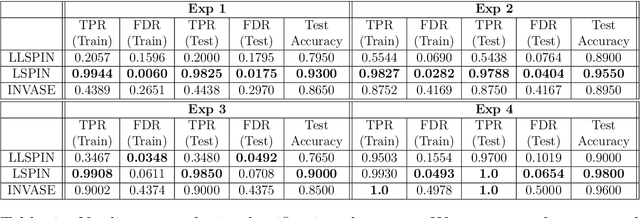


Despite the enormous success of neural networks, they are still hard to interpret and often overfit when applied to low-sample-size (LSS) datasets. To tackle these obstacles, we propose a framework for training locally sparse neural networks where the local sparsity is learned via a sample-specific gating mechanism that identifies the subset of most relevant features for each measurement. The sample-specific sparsity is predicted via a \textit{gating} network, which is trained in tandem with the \textit{prediction} network. By learning these subsets and weights of a prediction model, we obtain an interpretable neural network that can handle LSS data and can remove nuisance variables, which are irrelevant for the supervised learning task. Using both synthetic and real-world datasets, we demonstrate that our method outperforms state-of-the-art models when predicting the target function with far fewer features per instance.