 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal nearest neighbour classification with applications to semi-supervised learning
Paper and Code
Aug 24, 2018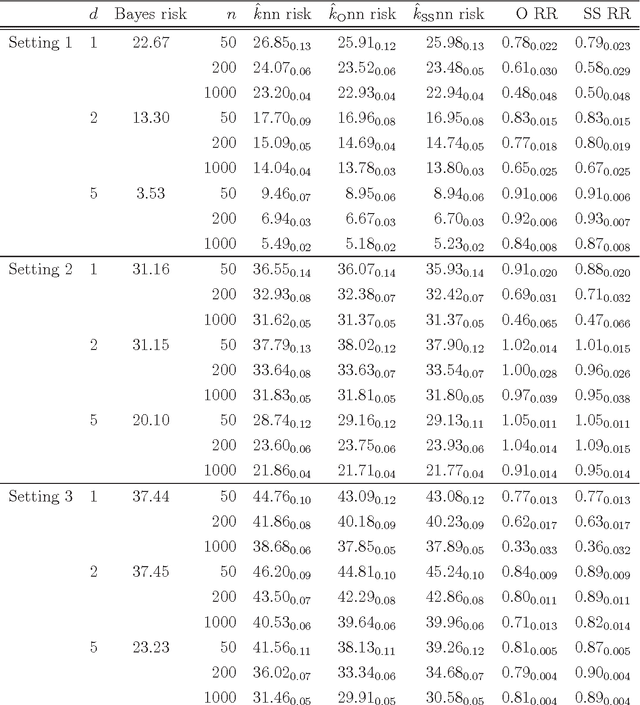
We derive a new asymptotic expansion for the global excess risk of a local $k$-nearest neighbour classifier, where the choice of $k$ may depend upon the test point. This expansion elucidates conditions under which the dominant contribution to the excess risk comes from the locus of points at which each class label is equally likely to occur, but we also show that if these conditions are not satisfied, the dominant contribution may arise from the tails of the marginal distribution of the features. Moreover, we prove that, provided the $d$-dimensional marginal distribution of the features has a finite $\rho$th moment for some $\rho > 4$ (as well as other regularity conditions), a local choice of $k$ can yield a rate of convergence of the excess risk of $O(n^{-4/(d+4)})$, where $n$ is the sample size, whereas for the standard $k$-nearest neighbour classifier, our theory would require $d \geq 5$ and $\rho > 4d/(d-4)$ finite moments to achieve this rate. Our results motivate a new $k$-nearest neighbour classifier for semi-supervised learning problems, where the unlabelled data are used to obtain an estimate of the marginal feature density, and fewer neighbours are used for classification when this density estimate is small. The potential improvements over the standard $k$-nearest neighbour classifier are illustrated both through our theory and via a simulation study.