 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Interpretation Methods to Machine Learning Using the Domain of the Feature Space
Paper and Code
Jul 31, 2019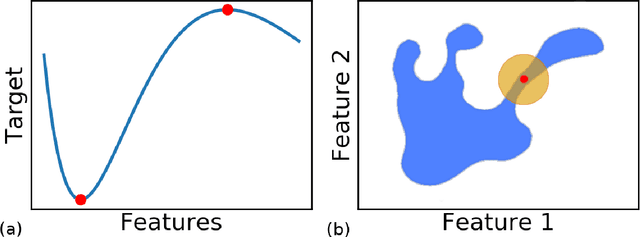
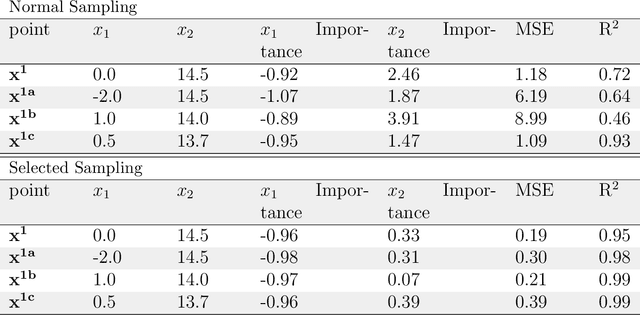
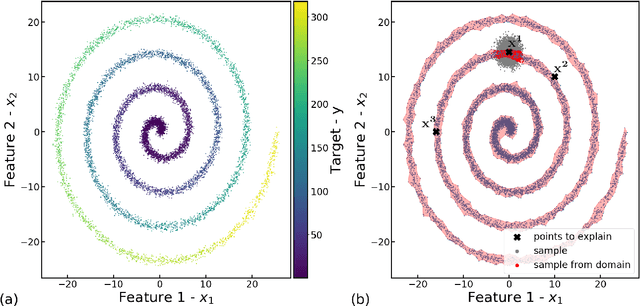
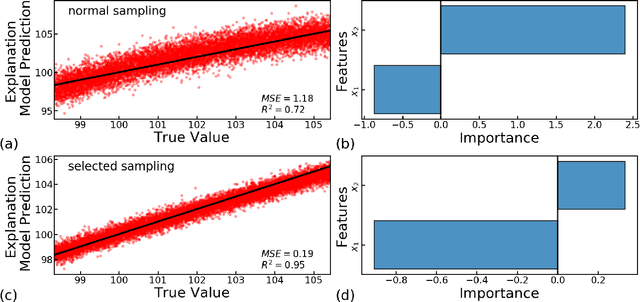
As machine learning becomes an important part of many real world applications affecting human lives, new requirements, besides high predictive accuracy, become important. One important requirement is transparency, which has been associated with model interpretability. Many machine learning algorithms induce models difficult to interpret, named black box. Moreover, people have difficulty to trust models that cannot be explained. In particular for machine learning, many groups are investigating new methods able to explain black box models. These methods usually look inside the black models to explain their inner work. By doing so, they allow the interpretation of the decision making process used by black box models. Among the recently proposed model interpretation methods, there is a group, named local estimators, which are designed to explain how the label of particular instance is predicted. For such, they induce interpretable models on the neighborhood of the instance to be explained. Local estimators have been successfully used to explain specific predictions. Although they provide some degree of model interpretability, it is still not clear what is the best way to implement and apply them. Open questions include: how to best define the neighborhood of an instance? How to control the trade-off between the accuracy of the interpretation method and its interpretability? How to make the obtained solution robust to small variations on the instance to be explained? To answer to these questions, we propose and investigate two strategies: (i) using data instance properties to provide improved explanations, and (ii) making sure that the neighborhood of an instance is properly defined by taking the geometry of the domain of the feature space into account. We evaluate these strategies in a regression task and present experimental results that show that they can improve local explanations.