 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Information Assisted Attention-free Decoder for Audio Captioning
Paper and Code
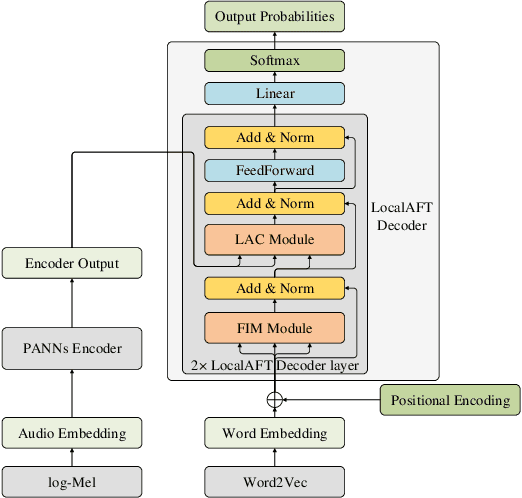

Automated audio captioning (AAC) aims to describe audio data with captions using natural language. Most existing AAC methods adopt an encoder-decoder structure, where the attention based mechanism is a popular choice in the decoder (e.g., Transformer decoder) for predicting captions from audio features. Such attention based decoders can capture the global information from the audio features, however, their ability in extracting local information can be limited, which may lead to degraded quality in the generated captions. In this paper, we present an AAC method with an attention-free decoder, where an encoder based on PANNs is employed for audio feature extraction, and the attention-free decoder is designed to introduce local information. The proposed method enables the effective use of both global and local information from audio signals. Experiments show that our method outperforms the state-of-the-art methods with the standard attention based decoder in Task 6 of the DCASE 2021 Challenge.